![[PIM] GradPIM: A Practical Processing-in-DRAM Architecture for Gradient Descent](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbSzSn1%2FbtrLhtcvslT%2FAAAAAAAAAAAAAAAAAAAAAP-5ET7GEu0-SpPlZpb8U6E_BP0xuLiJvNSCd_RXS-zC%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3D16qRcXIWBFCeBOhkze%252F05G6WKNA%253D)

Abstract
- 본 논문은 DNN의 parameter update를 가속화하는 processing in memory architecture인 GradPIM을 제시한다. GradPIM은 기존 memory protocol을 침해하지 않는 incremental simple design이다. bank-group parallelism을 활용하면 하드웨어 비용 및 성능 측면에서 PIM 모듈의 운영 설계가 효율적이다.
- 제안된 architecture은 DNN 훈련 성능을 향상시키고 memory bandwidth 요구사항을 크게 줄이는 동시에 protocol과 DRAM region의 최소한의 overhead만 가진다.
Introduction
- DNN의 중요성이 부상함에 딸, NPU는 inference, training을 위한 중요한 computing systems의 member가 되었다. NPU 성능을 달성하기 위한 핵심은 메모리(DRAM) bandwidth requriements를 최소화하는 것입니다. 단순하게 DNN을 실행하면 동일 data에 대한 반복적인 memory access로 인해 많은 memory traffic이 일어난다. 많은 NPU는 loop reordering과 PE array의 careful address mapping을 통해 reuse문제를 각기 다른 방식으로 해결한다.
- 또한 mixed-precision training은 계산 및 memory traffic을 모두 줄이는 데 도움이 되는 널리 사용되는 기술이다. 또한 minibatch serialization, BN fission & fusion, layer fusion은 memory traffic을 줄이기 위해 data reuse기회를 찾는 inter-layer optimizations이다.
- logic components와 DRAM을 동일한 die에 배치함으로싸 off chip 대역폭 병목 현상은 많은 PIM연구에서 입증되었듯이 상당히 완화될 수 있지만, PIM을 시장에 내놓는 것은 항상 어려운 도전이였습니다. 왜냐하면 CPU측에서 필요한 변경(ISA확장, 메모리 컨트롤러 지원)을 하는 것이 현재 생태계에 너무 파괴적이라는 것이였습니다. 하지만 생태계가 아직 고정되어 있지 않고 자체 NPU를 설계하려는 수많은 공급업체가 있기 때문에 NPU에서 그렇게 하는 것이 훨씬 더 쉬울 수 있다고 생각합니다. 이러한 상황에서 NPU는 PIM을 DNN execution ecosystem으로 들어오게 할 수있다.
DNN training을 위한 PIM의 3가지 목표
1. Fixed-function PIM, non-invasive to the existing protocol : 기존 protocol최대한 보존. 새로운 기능은 현재 메모리 컨트롤러 설계와의 충돌을 일으킬 수 있다.
2. Simple, memory-intensive functions : region overhead를 줄이고 열/전력 문제를 완화하면서 성능을 크게 향상시키려면 추가 기능이 간단하고 메모리 집약적이어야 한다.
3. Isolation of PIM components and DRAM cell array : cell array를 수정하면 기존 제품에 근복적인 설계 변경을 유발할 수 있기 때문에 피해야 한다.
위 목표를 고려하여 DRAM die 내에서 gradient descent logic을 지원하는 fixed-function PIM을 제안한다. data reuse에 대한 분석에 따르면, 최신 DNN workload의 매개변수 업데이트는 메모리 대역폭 요구 사항이 높다. 예를들어 ResNet-18의 경우 training중 전체 메모리 트래픽의 최대 50%을 소비한다. 매개 변수 업데이트의 이러한 메모리 집약적 특성은 PIM을 적절한 솔루션으로 만든다.
훈련의 다른 부분과 달리 업데이트 단계에 관련된 작업은 많은 설계에서 간과되어 왔다. 이러한 작업은 비교적 간단하며, 더 이상 최적화할 여지가 많지 않다. 그러나, 단순하고 메모리 집약적이기 때문에 메모리 내 프로세싱에 매우 적합하다. 본 논문에서는 매개 변수 업데이트 작업에 특화된 PIM 지원 메모리를 가진 mixed-precision accelerator를 지원할 것을 제안한다.
※ Mixed-Precision Training
개념적으로, 데이터 재사용 기법이 NPU내에서 순방향 및 역방향 작업의 트래픽을 분리하는 것 처럼 GradPIM을 사용하여 메모리 내에서 매개 변수 업데이트 단계와 관련된 메모리 트래픽을 분리하려 한다. (그림1)
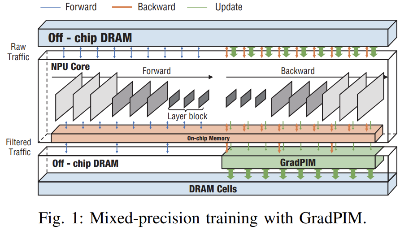
매개변수 업데이트 logic을 배치하기 위한 이상적인 장소로 bank group I/O gating을 생각한다. bank group 입출력 게이트 옆에 레지스터를 배치하여 각 bank group을 global DRAM구조에서 효과적으로 분리한다. 데이터 정렬을 통해 DRAM 내부 병렬화를 사용하여 매개 변수 업데이트를 수행할 수 있는 DDR기반 PIM작업 세트를 구현한다.
GradPIM은 기존 명령어를 변경하지 않고 기존 DDR4 protocol에서 단순하게 확장되도록 설계되었는데 이 설계는 DRAM cell array에 non-invasive하며, 주변 장치와 함께 작은 모듈만 배치합니다. 이러한 모듈은 메모리 컨트롤러에 의해 예약된 명령을 사용하여 완전히 제어되며, 따라서 GradPIM은 독립적인 가속기가 아닌 DDRM 호환장치로 간주될 수 있다.
논문 흐름
1. 대역폭 요구 사항을 줄이기 위한 현대적 최적화를 통해 DNN training 중 업데이트 단걔가 상당한 부분을 차지하며 실용적인 PIM설계의 휼륭한 대상이 될 수 있음을 식별한다.
2. DRAM 내부 대역폭을 활용하여 DRAM 내에서 매개 변수 업데이트 단계 작업이 실행될 수 있도록 각 bank group을 global 구조에서 분리하는 PIM logic을 설계한다.
3. DRAM 기술 하에서 레이아웃을 수행하여 제안된 PIM논리 설계를 모델링하고 배치의 면적과 오버헤드를 분석한다.
4. 최신 DRAM에 GradPIM을 배포하기 위한 데이터 배치 및 매핑 문제를 해결한다.
Motivation
- 대부분 NPU설계는 MAC활용도를 극대화하려고 forward, backword pass동안 memory traffic 최소화에 집중함.
- 통상적인 training절차를 고려할 때, 위의 전략은 괜찮지만 mixed-precision training과 몇가지 data reuse기술을 사용하면 매개 변수 업데이트에서 memory access가 급격히 증가한다.

- data reuse를 극대화하기 위해 계층 간 data traffic을 줄이기 위해 MBS, BNFF적용.
MBS(MiniBatch Serialization) 및 BNFF(Batch-Normalization Fission)
MiniBatch Serialization
Batch-Normalization Fission
계층이 뒤쪽으로 갈 수록 매개변수 업데이트로 인한 memory traffic의 비중이 커진다. 전체 훈련 동안 총 memory access의 22.4%를 소비하며, mixed-precision의 경우 45.9%를 차지한다. 이러한 관찰은 PIM모듈로 데이터 packing및 quantization하면 다양한 애플리케이션에서 속도와 에너지 이득을 가져올 수 있다는 [22]의 분석과 부분적으로 일치합니다. 훈련을 위한 quantization은 항상 정확한 accuary를 산출하지 못하지만 하드웨어 비용 절감의 유망한 방법으로 많은 NPU설계에 빠르게 채택되고 있습니다.
Background
DNN Parmeter Update Algorithms
대부분 DNN의 매개변수 업데이트 알고리즘은 SGD계열에 의존한다. 네트워크의 모든 매개 변수는 각 미니 배치 실행이 끝날 때 기울기의 음의 방향으로 업데이트 된다.
θt+1 = θt - θgt
여기서 gt는 현재 미니 배치에 대한 기울기 벡터이고 θ는 학습 learning rate이다. 더 빠른 수렴 및 더 나은 정확도를 얻기 위해 많은 advanced한 알고리즈을 제안되었는데, 예를들어 SGD+momentum은 다음과 같이 공식화 된다.
vt = αvt−1 −ηgt
θt+1 = θt +vt
여기서 α는 momentum decaying factor이고 v는 momentum이다. momentum은 감쇠 인자로 작용해 수렴 속도를 높입니다. 가중치 감쇠항 β를 추가할 경우, 위 수식은 다음과 같습니다.
vt = αvt-1 - β µt +gt
Adam, AdaGrad, RMSprop등 몇 가지 업데이트 알고리즘이 더 있습니다. 일반적으로 learning rate (0.01)과 같이 hyperparameters이 작기 때문에 더 높은 정밀도가 필요하다. 따라서 이는 특히 mixed-precision DNN training에서 쉽게 bandwidth bottleneck으로 작용할 수 있다. [?]
Modern DRAM Architecture
DRAM은 1T1C cell의 2D 배열인 여러 뱅크로 구성되며, 뱅크의 셀 행은 wordline을 공유하며, wordline은 활성화해야할 행을 선택하는 데 사용된다. 뱅크의 수직 열 bit line을 공유한다. 행이 활성화되면 각 셀 내에 저장된 작은 전하가 비트라인으로 흘러나와 일련의 감지 증폭기에 의해 잡힌다. sense amp는 cell capacitor를 원래 값으로 복원하고, 이를 완료하려면 tRAS의 시간이 필요합니다.
활성화된 행에서 데이터를 읽으려면 몇 개의 비트(열)가 선택된다. 활성화 시작부터 tRCD를 실행한 후 활성화된 행에서 데이터를 읽을 수 있다. 열이 선택되고 I/O gate를 통해 off chip data bus로 전파된다. 각 bank가 독립적으로 작동할 수 있더라도 I/O gate는 그들 간에 공유되며, 각 열 읽기 명령은 tCCD에 대한 I/O gate를 차지하기에 연속 열 읽기 명령은 tCCD로 간격을 두어야 합니다.
또한 데이터는 tBURST를 위한 off chip data bus를 차지한다. tCCD와 tBURST는 일반적으로 4cycle로 설정되며, burst1에 64byte의 데이터를 제공한다. read command로 부터 tCL후에, 데이터 버스트는 데이터 버스에서 시작된다. (열 쓰기의 경우 반대 방향) 메모리 컨트롤러는 write command이후 tCWL단위로 데이터를 배치할 수 있으며, tCCD이후 I/O gate가 다시 점유된다.
읽기 또는 쓰기 명령을 위해 다른 행에 액세스해야 하는 경우 현재 행을 비활성화하고 새 행을 열어야 한다. 그러나 이전 읽기 또는 쓰기 명령이 열에서 진행 중인 경우, 행은 읽기에 대한 데이터를 제공해야 하거나 쓰기를 위해 데이터가 복원될때까지 기다려야 하기 때문에 이전 읽기/쓰기 명령 이후 각각 tRTP or tWR에 대해 행을 열어 두어야 한다.
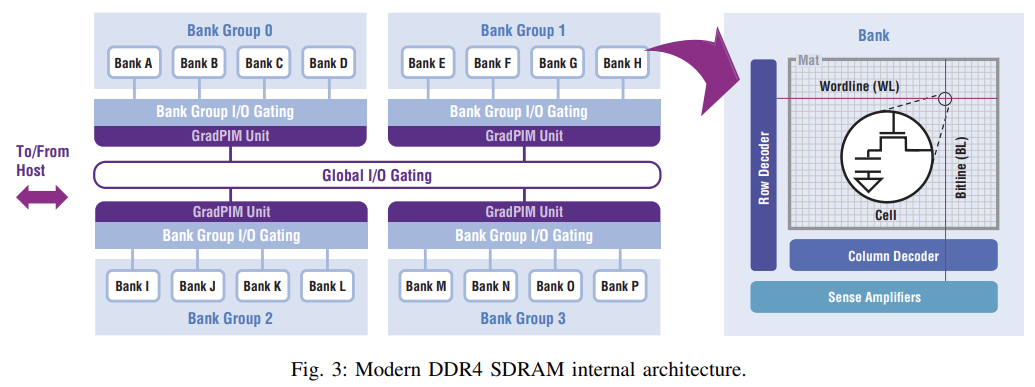
DDR4부터 도입된 중요한 개념은 bank group입니다. off chip data 속도가 증가함에 따라 내부 fetch속도를 유지하기 위해 여러 bank가 bank group을 형성하고 I/O gate는 bank group I/O gate와 global I/O gate로 분할 됩니다. 결과적으로 연속 열 액세스가 두 개의 서로 다른 뱅크 그룹에 할당되는 경우, 액세스는 global I/O gate만 공유하며, 이전 세대(DDR3)와 같이 4cylce의 tCCD_S로 공간을 확보할 수 있습니다.
그러나 이러한 액세스가 단일 bank group에 대한 access일 경우 data가 bank group I/O gate와 global I/O gate를 모두 차지하므로 이제 두 access를 더 긴 간격(tCCD_L)으로 설정해야합니다.(S에 비해 25%~100% 길다.)
bank group의 도입으로 in-DRAM processing in memory(PIM)기술에는 두가지 기회.
1. bank-level parallelism은 각 bank에 독립적으로 access할 수 있으며, 단일 bank만으로도 off chip data bus의 절반 이상 대역폭을 제공할 수 있다. 따라서 16개의 bank가 있는 DDR4 SDRAM은 8배 이상의 bank 내부 대역폭을 가지며 채널 당 rank의 수를 곱한다. 한편 각 bank group은 off chip data bus의 절반 이상의 대역폭을 제공할 수도 있다. 따라서 2배(DDR4) 또는 4배(DDR5)이상의 bank group 내부 대역폭이 있으며, 다시 rank의 수를 곱한다. 각 bank group은 여러 bank에 접근할 수 있으므로 별도의 bank에서 여러 개의 열린 행으로 작업할 수 있는 기회를 제공하는데, 이는 bank parallelism만으로 작업할 때는 불가능 했던 것이다.
GradPIM
DRAM내에서 MAC연산을 수행하는 많은 PIM작업과 달리 MAC연산을 host NPU에 전적으로 맡긴다. 대신 GradPIM은 매개 변수 업데이트 단계를 수행한다.
GradPIM Architecture
다음 그림은 GradPIM의 architecture을 보여준다. GradPIM은 각 bank group의 local I/O gate 옆에 배치된다. GradPIM중심에는 temporary register가 있다. local, global I/O gate를 분리해 bank-group level paralleism을 지원한다. GradPIM은 외부 data bus를 점유하는 대신 temporary register를 읽거나 쓴다. 또한 업데이트 단계에 필요한 벡터 연산도 수행한다.
GradPIM을 bankgroup I/O gate 옆에 배치하는 또 다른 이점은 여러 뱅크로 access할 수 있다는 것이다. 즉, bank내에서 작업을 수행하는 이전의 몇 가지 PIM접근 방식과 달리 GradPIM은 한 번에 여러 행에서 동시에 작동할 수 있다.
GradPIM logic은 주로 Register, Scaler, Parallel arithmetic unit을 포함한다.
- Register는 중간 결과를 저장하는데 사용되며 global sense amp와 너비가 동일(rank별 64Byte)하다. GradPIM은 산술연산의 소스와 대상에 사용할 GradPIM유닛당 두 개의 temporary register와 quantization register를 배치한다.
- Scaler는 default learning rate와 같은 미리 정의된 hyperparameters를 사용하여 데이터를 스케일링하는 데 사용된다. 스케일러는 bankgropu I/O와 레지스터 사이에 배치되며 요소별 곱셈을 수행한다.
- Parallel arithmetic unit은 업데이트 단계 내에서 위 방정식과 같은 요소별 계산을 수행하는 데 사용된다.

GradPIM Operations
1. 스케일링된 읽기 로드는 레지스터에 셀의 데이터 열을 로드한다. 레지스터를 로드하는 동안 값은 식4에서와 같이 y,α 또는 β와 같은 특정 hyperparameter에 의해 스케일링 된다. 이러한 값들은 고정 상수이기에, 우리는 각 값에 대한 id에 4개의 스케일러 값을 고정한다. 스케일러는 단순화하기 위해 2n±2m 단위로 근사하고 시프터와 가산기로 스케일러를 구현한다. 각 opcode에 할당된 n과 m의 값은 사용자가 서로 다른 값 집합을 필요로 하는 경우 MRW(Mode Register Write)명령을 사용해 프로그래밍할 수 있다.
2. 병렬 연산은 레지스터에서 산술 연산을 수행하고 다른 레지스터에 결과를 넣습니다. 식4의 부분 항을 생성하거나 양자화된 값과 비양자화된 값 사이의 변환을 실행하기 위해 덧셈, 뺄셈, 양자화 및 비양자화를 지원한다. 양자화는 임시 레지스터 중 하나에서 데이터를 읽고 양자화 레지스터에 쓰거나 역양자화를 위해 그 반대를 취한다. 양자화된 값이 레지스터에서 더 오래 유지되기 때문에(8bit 양자화 : 4회) 전용 레지스터를 사용하면 데이터 및 제어 경로 회로 설계가 크게 간소화된다. (섹션 5참고)
3. Writeback. 최적화 작업에 대한 작업이 완료된 후 결과를 다시 기록해야 한다.
Timing Considerations
메모리 컨트롤러가 기존 명령과 함께 GradPIM명령을 스케줄링 할 수 있도록 각 GradPIM 명령이 타이밍 매개 변수와 혼합되어야 한다.
- 스케일링된 읽기는 일반적으로 DDR protocol의 열 읽기 작업과 유사하지만, 데이터는 데이터 버스 대신 레지스터 중 하나에 배치되므로 tBURST를 사용하여 다른 명령의 스케줄링을 제한하지 않는다. 메모리 컨트롤러는 기존 DDR 명령과 밀접한 일관성을 유지하기 위해 메모리 컨트롤러는 tCCD_L이후 동작이 완료된 것으로 간주한다. tCCD_L은 bank 또는 bank group이 제공할 수 있는 대역폭을 나타냅니다. 스케일링된 읽기 작업도 bank에서 데이터를 읽기 때문에 데이터를 일고 레지스터에 저장하기 위해 tCCD_L을 할당한는 것이 합리적이며 sense amp는 cell로부터 데이터를 제공해야하기 때문에 tRTP는 여전히 보존됩니다. 스케일링된 읽기는 local bank group I/O gate만 차지하므로 다른 bank group의 다른 스케일링된 읽기 명령과 간섭하지 않는다.
- 병렬 산술 연산은 기존의 DRAM logic에서 완전히 벗어나며 기존 타이밍 매개변수에 의해 제어되지 않으므로 점유중인 병렬 ALU를 설명하기 위해 산술 연산에 대한 최악의 경우 실행시간을 나태내는 추가 타이밍 매개변수 tPIM을 도입합니다. 이 타이밍 매개변수는 다른 명령을 간섭하지 않지만 동일한 bank group내에서 다른 PIM산술 연산이 수행되지 않도록 해야합니다.
- Writeback동작은 기존 writeback명령의 후반부로 간주될 수 있다. 데이터 버스 대신 데이터는 레지스터 중 하나에서 온다. 따라서 writeback동작은 tCWL또는 tBURST의 영향을 받지 않지만, bank group I/O gate가 점유될때 tCCDL을 스케일된 판독값과 동일하게 유지한다. tWR은 sense amp를 통해 행으로 데이터가 전파되기 때문에 writeback이후 행을 닫아야하는 경우 이를 준수해야 한다.
Update Phase Procedure
- NPU가 먼저 weight에 대한 backword pass에 의해 생성된 gradient를 memory에 쓴 후 식3,4에 보여진 것 처럼 parameter update를 한다. update후 NPU는 다음 단계 forward를 위해 updated된 weigth를 읽는다.
- mixed-precision training을 위해 parameter update 알고리즘 전후에 quantization/dequantization가 수행되므로 GradPIM은 high precision data를 작업하고 NPU는 low precision data를 작업할 수 있다.
다음 그림은 8bit/32bit mixed-precision을 가정해 4-b에 설명된 작업을 사용해 프로세스가 순차적으로 수행되는 방법을 보인다.

1. Dequantization
그림 상단은 Dequantization을 수행하는 절차이다. quantization된 gradient Q(g)와 dequantized gradients g에 대한 행이 동시에 액세스할 수 있도록 bank group내의 다른 bank에서 이미 열려 있다고 가정한다.
1. Q(g)가 quantize register에 load.
2. Q(g)열의 1/4을 quantize하고 그결과를 temporary register에 기록한다. Dequantization명령은 quantize register에서 읽어야 하는 열의 1/4과 쓸 temporary register를 지정한다.(4-e)
3. row에 gradient(g)를 다시 쓰고, 전체 column이 dequantized될때까지 2번째 동작을 4번 반복한다. 이 절차는 g의 연속 열에 대해 반복된다.
2.Parameter Update
중간 그림은 SGD+momentum algorithm을 사용하여 GradPIM으로 update하는 단계를 수행하는 절차를 보여준다. (마찬가지로 weigth paramter θ, momentum v, gradient g에 대한 행이 이미 bank group 내의 다른 bank에서 활성화 되었다고 가정한다.)
1. A column of g(t) and v(t−1)는 scaled operation을 사용해 η 및 α로 scaling된 후 temporary registers에 load된다.
2. 위의 두 register의 scaling된 값은 parallel_add으로 처리된다.
3. column of θ(t)은 ηβ로 scaled된 후 temporary register에 load된다.
4. parallel_add연산이 한번 더 수행되어 식4의 v(t)를 만든다.
5. writeback
6. θ(t+1)도 마찬가지로 동작.
전체 행이 처리될 때까지 연속 column에 대한 g,v,θ 수행을 반복한다. (1~6)
이 절차에서 dequantization경우 불필요한 row activation이 필요하지 않다. 가중치 파라미터당 두 개 이상의 모멘텀이 사용되는 더 복잡한 알고리즘은 동시에 open된 row수가 증가할 수 있지만 일반적인 DDR4/5 SDRAM에는 bank group당 4개의 bank가 있으며 우리가 아는 대부분의 SGD기반 매개변수 update 알고리즘에서의 모든 강중치당 값을 포함하기 충분한다.
3. Quantization
마지막 단계로서 master weight parameters는 forward및 backword단계에서 NPU가 읽을 수 있도록 낮은 정밀도로 Quantization된다. 이 절차는 dequantization과 비슷하지만 순서는 반대이다.
1. weight parameter column들이 temporary register에 load되고 quantization이 수행된다. quantization register의 1/4을 채워서 4번 반복한다.
2. quantization register가 꽉 찰때마다 Q(θ)로 다시 행에 쓴다. (연속된 열에 대해 반복)
E. Commanding GradPIM
기존 DDR4 protocol에서 RFU(향후 사용을 위해 예약)명령을 사용해 기존 명령을 수정하지 않고 GradPIM명령을 실현한다. RFU작동을 위한 다수의 구성 가능한 명령 신호가 있는데, 모든 명령에는 bank group, bank, row 및 colunm에 대한 주소가 필요하므로 GradPIM명령 구성에는 5개의 신호가 있는 이는 TABLE1에서 나타내고 있다.
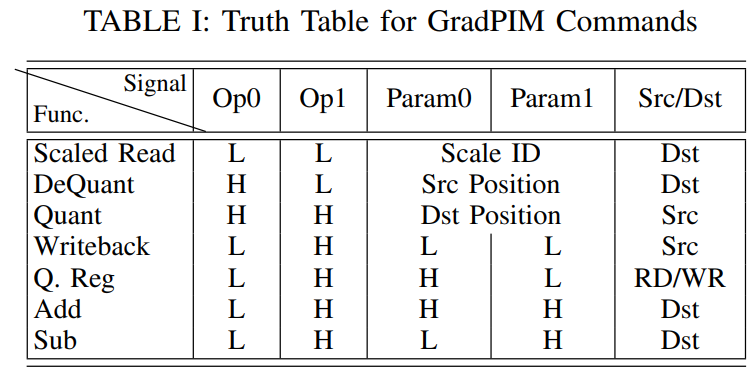
TABLE1은 추가된 command의 진리표를 보여준다. sclaed read의 경우 scaler value에 2bit를 할당하고 dst register에 1bit을 할당한다. quantization및 dequantization를 위해 2bit quantize register내의 offset을 선택하기 위해 할당되며, 다른 bit는 src/dst temporary register id에 할당된다. writeback 및 add ops의 경우 1bit가 src또는 dst register id를 나타내기 위해 할당된다. 병렬 ops는 피연산자로 사용되는 두 개의 temporary register만 있기때문에 src register id를 필요로 하지않고, quantize register 제어를 사용하기 위해 wr/rd에 단일 bit를 할당한다.
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!