

-CT의 원리
CT(Computed tomography)는 X-ray를 이용하여 몸의 단면을 촬영하고 컴퓨터를 통해 영상화하는 영상진단기법입니다.
-Reconstruction(재구성)
재구성하기 위한 대표적인 2가지 방법
1. lterative algorithm
이 방식은 여러 각도에서 더한 값들을 이용해 각각의 intensity를 찾아내는 방식이다. 이 방식은 아주 정확한 값을 도출한다는 장점이 있지만 연산시간이 느리다는 단점이 있습니다.

2. Filtered backprojection algorithm
Lterative algorithm의 단점으로 인해 대부분의 CT가 이 방식을 따릅니다. 각도별로 projection해 sinogram을 만들고 filter를 곱해 filtered된 sinogram을 만듭니다. 그 다음 back-projection을 수행합니다.


- interpolation
이미지 처리에서 픽셀 좌표는 간격이 1인 2차원 그리드의 교차점으로 볼 수 있습니다. 이미지를 확대하거나 축소 할때, 픽셀과 픽셀 사이 구간에서 값이 필요한 경우가 생기는데 interpolation이란 픽셀 사이 구간 주변의 알고있는 값들을 이용하여 구간사이의 값을 유도하는 과정을 뜻합니다.
Interpolation의 종류
1. Nearest Neighbor interpolation
가장 가까운 화소값을 사용하여 연산이 빠르지만 경계선이 모호해지며 해상도가 높지 않다.
2. Bilinear interpolation
인접한 4개의 픽셀의 픽셀값과 거리비를 사용하여 결정
3. Bicubic Interpolation
인접한 16개 픽셀의 픽셀값과 거리에 따른 가중치의 곱을 사용하여 결정
- 딥러닝 기반 Super Resolution 기술의 현황 및 최신 동향
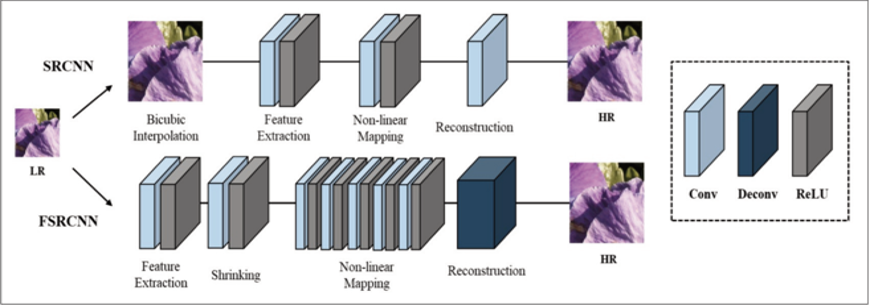
SRCNN 모델
초해상화 분야에 최초로 딥러닝 기반의 CNN을 적용한 모델입니다. 이전의 초해상화 연구는 각각의 단계를 처리하는 여러 알고리즘들을 종합적으로 합쳐서 초해상화를 수행하는 반면 SRCNN은 최초로 모든 단계를 하나의 통합된 네트워크에서 처리하였습니다. 입력 LR영상으로는 Bicubic interpolation을 적용해 업스케일링 된 이미지를 사용해 CNN 네트워크를 통과하면서 영상의 해상도에 변화가 없습니다.
단순한 3계층의 구조를 하고 있으며, 첫번째 층은 Patch Extraction역할로 LR영상에서 패치들을 추출하여 feature map단위로 표현합니다.
두번재 층에서는 각각의 feature map을 또 다른 feature map으로 비선형 매핑을 하는 역할을 합니다. 마지막층에서는 비선형적으로 매핑된 feature map들을 바탕으로 HR영상을 생성합니다.
FSRCNN 모델
SRCNN을 조금 개선한 모델이며 입력으로 들어가는 LR영상을 bicubic interpolation을 사용하지 않고 그대로 네트워크에 넣는 방식을 사용했습니다. 기존 SRCNN에서 입력 LR영상의 해상도를 출력 HR영상의 해상도로 업스케일링 시킨뒤 CNN연산을 하는 과정이 매우 비효율적이기 때문입니다. FSRCNN 네트워크에서는 영상의 해상도를 변화하기 위해서 Deconvolution 층을 사용해 feature map의 가로 세로 크기를 키워 원하는 해상도로 출력 영상을 늘릴 수 있었습니다.
잔여 학습을 통한 네트워크 설계
일반적으로 깊은 네트워크를 학습 시 역전파 과전에서 입력층으로 갈수록 기울기가 점차적으로 소실되는 Gradient Vanishing과 기울기가 비정상적으로 커지는 Gradient Exploding문제가 발생해 파라미터들이 제대로 학습이 되지 않는 문제가 발생할 수 있습니다. 이러한 문제를 해결하기위해 잔여학습(Residual Learning)이라는 새로운 학습 방법이 등장하였습니다.
잔여학습은 입력 LR영상을 최종 출력 HR영상에 더해주고 두 영상의 차이 값을 학습하는 방법입니다. 일반적으로 입력LR영상과 출력HR영상은 비슷하기 때문에 그 차이 값은 매우 작거나 0이므로 기울기소실/폭주 문제를 해결할 수 있었습니다.
VDSR모델
잔여학습을 적용한 모델 SRCNN과 마찬가지로 bicubic interpolation으로 업스케일링 된 입력 LR영상과 출력 HR영상을 네트워크 학습 시 사용합니다. 그러나 SRCNN과 다르게 입력 LR영상과 출력 HR영상의 차이를 네트워크에 입력하여 마지막 출력단에서 입력 LR영상을 더해준다는 차이점이 있습니다. 이렇게 학습을 진행한다면 단순히 덧셈이 추가되는 형태로 연산을 단순화할 수 있고 깊은 네트워크에서 쉽게 최적화가 가능합니다.
EDSR 모델
VDSR과 마찬가지로 잔여학습을 이용해 보다 깊은 네트워크로 구성되어 있습니다. EDSR은 32개 이상의 층을 사용하였고 채널 수도 기존의 다른 네트워크 대비 4배 이상늘려 파라미터 수도 그에 비례하여 매우 많이 증가하였습니다. 깊어진 네트워크를 보다 안정적으로 학습하기 위해 네트워크를 잔여 블록(Residual Block)별로 나누고 각각을 Skip Connection을 사용해 연결하여 파라미터들이 더 쉽게 최적화되도록 설계하였습니다. 또한 각각의 잔여블록 안에서 feature map들이 더해지면서 feature map들의 분산이 커지는 경우가 생겨 학습이 잘 안되는 문제를 해결하기 위해 일정한 상수값을 CNN층 이후에 곱해주는 Multi을 추가하였습니다. EDSR에서는 SPCNN을 사용해 학습과정에서 입력 LR영상의 해상도를 키웠습니다.
SPCNN은 CNN층을 거친 뒤 마지막 층에서 feature map의 개수를 업스케일링 배수의 제곱 개만큼 늘려준 뒤 이를 픽셀 셔플연산을 통하여 적절히 배치하여 원하는 해상도의 출력 HR영상을 복원해낼 수 있습니다.이는 bicubic interpolation사용한 VDSR대비 효율적인 연산과 정확도 또한 높아진 효과를 보였습니다.

생산적 적대 신경망을 통한 네트워크 설계
기존의 지도학습 기반의 딥러닝 네트워크가 아닌 비지도 학습 기반의 GAN을 사용하여 초해상화 문제를 해결하려는 시도를 하였습니다.
SRGAN 모델
SGGAN네트워크는 이미지를 복원하는 생성(Generator)네트워크와 학습 시 GT(Ground Truth)영상과 출력 HR영상을 비교하여 구분하는 분류(Discriminator)네트워크로 구성되어 있다. 또한 학습 시 기존 MSE losse대신 기존의 딥러닝 기반의 영상분류 네트워크 중 하나인 VGG net을 사용하여 Perceptual loss를 통해 인지적으로 보다 뛰어난 영상을 얻을 수 있도록 학습할 수 있습니다.
Perceptual losss란 입력과 GT를 미리 학습해 놓은 다른 딥러닝 기반의 영상 분류 네트워크를 통과 시킨 후 얻은 feature map 사이의 손실을 최소화 하는 방향으로 파라미터를 학습합니다. 생성 네트워크에서는 학습을 통해 출력 HR영상을 복원해내고 분류 네트워크는 해당 생성 이미지를 GT와 비교하여 최대한 정확도가 높은 방향으로 전체 GAN네트워크를 학습시키게 됩니다.

- slice thickness을 줄이기위한 딥러닝 기법
[Deep Learning Algorithm for Reducing CT Slice Thickness: Effect on Reproducibility of Radiomic Features in Lung Cancer]논문을 활용해 정리해보았습니다.
Radiomic Feature은 의료영상을 기반으로 수많은 정량화된 값들을 추출하여 임상적 결정에 사용하려는 영상처리 기법으로 Slice thickness등의 인자에 영향을 많이 받는 것으로 알려져 있습니다.
CNN-Based SR Technique
네트워크는 사전처리, 비선형 매핑, 재구성부분으로 이루어집니다. 사전처리단계는 다양한 스케일의 입력이미지의 변화를 다루고, 비선형 매핑과 재구성 단계에서는 저해상도(3또는5mm)의 입력이미지와 타겟이미지(1mm)의 차이를 처리합니다.
척도가 다른 입력 이미지로부터 변동을 처리하는 전처리 부분은 5x5 커널과 64채널(하나는 3mm용 , 하나는 5mm용)으로 구성된 두개의 잔여블록(resblock)으로 구성됩니다.
비선형 매핑 부분은 두개의 긴 연결장치로 구성되며, 두개의 연결장치 모두 3x3커널과 64채널이 있는 4개의 resblock이 있습니다.
재구성 부분은 3x3 Convolution layer 및 하위 픽셀 셔플 layer를 사용하여 깊이 방향으로 축 영상 수를 3배 or 5배 확장했습니다.
SR 네트워크에는 두가지 주요한 특성이 있는데 첫번째 특징은 저해상도 입력이미지 (3,5mm)와 대상이미지(1mm)의 차이에 대해 훈련할 수 있는 기능으로 , 서브픽셀 셔플링(subpixel shuffling)기능을 사용하여 라벨 이미지를 저해상도 이미지로 변환합니다. 두번째 특징은 모든 컨볼루션 계층이 3차원으로 되어 있고 성능 향상을 위해 배치 정규화 계층이 사용되지 않았습니다.

CNN 기반 SR알고리즘이 기존 단순보간 알고리즘보다 나은지 확인하기 위해 절편의두께를 변환하는 trilinear interpolation algorithm을 적용하였습니다.
밑은 GT와 변환된 이미지 및 difference map을 나타낸것입니다. Difference map에서 녹색은 0, 파란색은 음수, 빨간색은 양수를 의미합니다. 원래 1mm영상과 SR3mm 영상을 비교할때 대부분의 경우 거의 0에 가까운 차이를 보입니다. (root-mean-square error:30.83HU)

참고)
CT의 기본이해
https://scienceon.kisti.re.kr/srch/selectPORSrchArticle.do?cn=JAKO201266452656955&dbt=NART
Filtered backprojection algorithm
https://github.com/csheaff/filt-back-proj
Slice thickness를 줄이기 위한 딥러닝 기법
https://www.kjronline.org/pdf/10.3348/kjr.2019.0212
https://scienceon.kisti.re.kr/srch/selectPORSrchArticle.do?cn=DIKO0015088183&dbt=DIKO
딥러닝 기반 Super Resolution 기술의 현황 및 최신 동향
http://www.kibme.org/resources/journal/20200504094149078.pdf
'DNN > 컴퓨터 비전' 카테고리의 다른 글
| RIFE 모델을 이용한 Video Frame / Image Interpolation (0) | 2021.09.28 |
|---|---|
| 10) SSD(Single shot Detector) (0) | 2021.08.17 |
| 9) Faster RCNN (1) | 2021.08.16 |
| 8) Fast RCNN (0) | 2021.08.16 |
| 7) SPP( Spatial Pyramid Pooling) Net (0) | 2021.08.16 |
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!



