![[CUDA] Thread할당](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbsBQVU%2FbtrPP7CJcjY%2FAAAAAAAAAAAAAAAAAAAAANoQ1UbtcgzE17izihbL671lBHEuw6BcuJh1D4VfqKSd%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3Dumj8oxtL1XXJUZz2bpC54BHo1I8%253D)

Cuda kernel 함수를 개시하면, kernel function을 수행하는 thread들이 grid를 형성한다. kernel 함수는 program 실행 중 kernel이 개시될때 생성되는 thread들이 수행할 C문장을 정의한 것이다. grid내부의 thread들의 구성과 자원할당, 스케줄링을 살펴본다.
CUDA thread의 구성
- grid내부 thread들은 모두 동일한 kernel fuction을 실행하기에 서로 구별하고 사용할 data영역을 구별하기 위해 고유한 좌표값(blockIdx, threadIdx)를 사용한다.
- blockIdx, threadIdx는 kernel 함수에서 사용할 수 있도록 이미 초기화된 변수로 주어진다. 즉, thread가 kernel 함수를 수행하는 도중 blcokIdx, threadIdx를 참조해 thread의 좌표값을 얻는다.
- gridDim, blockDim도 이미 정의된 변수들로 각각 grid, block의 크기를 알려준다.

그림 1을 기준으로 보면 gird는 N개의 thread blcok으로 구성되어 있으며(0~N-1의 blcokIdx.x) 각 thread block은 M개이 thread로 구성되어 있다. (0~M-1의 threadIdx.x) => 각 grid당 MxN의 thread가 존재한다.
각 code는 threadID=blcokIdx.x * blockDim.x + threadIdx.x의 식으로 계산된 값을 이용해 input data를 읽을 위치와 output data를 쓸 위치를 알 수 있다.
thread 계산의 예)

일반적으로 gird는 2차원 배열, block은 3차원 배열의 thread로 구성된다. 이는 kernel이 실행될때, 정해진다.

다음은 host code에 의해 개시되는 작은 크기의 2차원 grid를 나타내고 있다.

Idx의 용도
" blockIdx와 threadIdx는 동일한 kernel을 실행하는 thread들을 구별하기 위한 수단이며, thread가 작업을 수행할 data영역을 결정하는 것이다. "
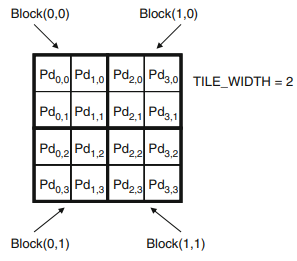
만약 blockIdx를 사용하지 않는다면, 각 block은 최대 512개의 thread를 가질 수 있으므로 최대 512개의 Pd원소만 계산할 수 있다. 즉, 16*16의 연산은 가능하지만, 32*32연산은 한번에 처리하지 못한다. => 더큰 matrix를 수용하기 위해 여러개의 thread block을 사용할 필요가 있다.
cuda에서의 행렬 곱 연산
- Pd를 정방향 타일로 나눈다. 타일의 모든 Pd원소는 동일한 block의 thread에 의해 계산된다.
- thread는(bx*tile_width+tx)를 이용해 Pd의 x index, (by*tile_width+ty)를 이용해 Pd의 y index를 찾는다.

각 thread block안에서 수용되는 곱셈의 동작

- blcok(0,0)의 thread들은 4개의 내적값을 생성.
- thread(0,0)은 Md의 행0과 Nd의 열0의 내적 연산을 하여 Pd(0,0)을 생성한다. 그림 6은 다수의 block을 사용하도록 수정된 kernel함수이며, blockIdx,threadIdx값을 사용해 계산할 Pd의 row, col을 찾는다. 그림 9은 수정된 kernel을 개시하는 host code이다.



Thread의 할당
kernel이 개시되면 cuda system은 해당되는 thread의 grid를 생성한다. 이 thread들은 block단위로 실행 자원에 할당된다.
- 각 SM은 block이 필요한 충분한 자원을 가지고 있는 한 최대 8개까지의 block을 할당한다. 예를들어 SM이 30개가 있다면 최대 240개의 block을 동시에 할당할 수 있다. 대부분 grid는 240개보다 더 많은 block을 가지는데 runtime system은 실행해야하는 block list를 관리하면서 이전에 할당된 block이 끝나게 되면 새로운 block을 SM에 할당하는 방식을 사용한다.
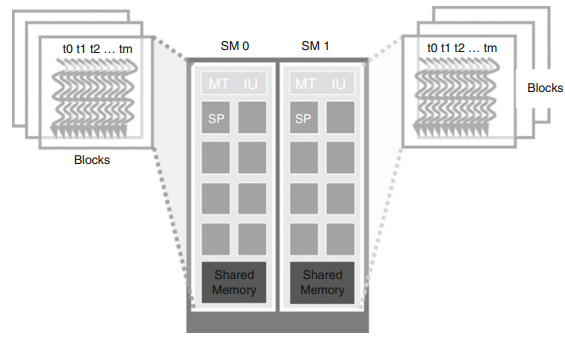
그림10을 기준으로 보면, 각 SM에 3개의 thread block을 할당했음을 알 수 있고, 동시에 SM자원 제약 중 하나로 작용한다. SM이 thread와 blcokId의 실행상태 추적을 위한 자원은 필수적이여한다.
Thread 스케줄링 & 지연시간
thread scheduling은 구현에 속한 개념이기에, 특정 hardware구현에 대해 설명이 필요하다. 하나의 blcok은 하나의 SM에 할당되며, warp라 불리는 32개의 thread unit으로 나눠야한다. SM에서 warp은 thread schdeuling의 단위이다.

그림 11은 하나의 block이 warp로 나누어진것을 볼 수 있다. 각 warp는 연속된 threadIdx값을 갖는 32개의 thread로 구성된다.(0~31 : 1번째 warp, 32~63 : 2번째 warp) 각 block이 256개의 thread를 가지고 있다면 각 block은 256/32 = 8개의 warp를 가지고 있을 것이다.
한 SM에서 많은 warp를 가져야되는 이유는 global memory를 접근하는 것과 같이 지연시간이 긴 연산을 CUDA device가 효율적으로 처리하기 위해서이다. 긴 지연시간이 발생했을때 다른 thread의 작업으로 그 latency를 overlap하기 위해서이다.
'Computer Architecture > GPU' 카테고리의 다른 글
| [CUDA] 성능 고려 사항 (1) | 2022.10.29 |
|---|---|
| [CUDA] 병렬성의 제약조건 (0) | 2022.10.29 |
| [CUDA] CUDA Memory (0) | 2022.10.29 |
| [CUDA] 기초 (0) | 2022.10.29 |
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[CUDA] 성능 고려 사항](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbMILa7%2FbtrPPMy6KOz%2FAAAAAAAAAAAAAAAAAAAAAAFq00v8gZpJaYENT4Dz1nlVy585914-ZWBT5C6qmRJ9%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3DA1ouoOHIK5KU0iNqZZ9VOCu3qvA%253D)
![[CUDA] CUDA Memory](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fci2YZu%2FbtrPPOQW8wd%2FAAAAAAAAAAAAAAAAAAAAAHkBpyDiG62tDjHcROYPPapvGlT0fdIistAXJMjWm7ee%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3DTnEu62T3Je5hjIjoQPAJyFt5Xe8%253D)
![[CUDA] 기초](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbZQgW2%2FbtrPP8g9WEy%2FAAAAAAAAAAAAAAAAAAAAACbA-743tPyIOyvxp2In22pl5lNwwXAGoMoyVScRehyL%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3D5NsItB1%252B2emVabpZFYB7f04Tx24%253D)