![[CUDA] CUDA Memory](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fci2YZu%2FbtrPPOQW8wd%2FAAAAAAAAAAAAAAAAAAAAAHkBpyDiG62tDjHcROYPPapvGlT0fdIistAXJMjWm7ee%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3DTnEu62T3Je5hjIjoQPAJyFt5Xe8%253D)

thread들에 의해 수행되는 data들은 일단 host memory로부터 device의 global memory로 옮겨진다. 그리고 나서 thread들은 자신의 blockIdx와 threadIdx를 사용해 data중 자신이 처리해야하는 부분을 접근한다.
=> 이런 간단한 cuda kernel로는 hardware의 잠재적인 최대성능을 아주 일부분만 얻을 수 있다. DRAM으로 구현된 global memory의 접근 지연시간이 매우 길고 접근 대역폭도 제한적이기 때문이다.
gobal memory로의 접근이 지나치게 많아져 data flow가 정체되는 상황이 발생할 수 있다. 즉, SM들 중 일부는 놀고 있을 수 있다. cuda에서는 memory접근을 위한 추가적인 방법을 제공하고있다. (cuda kernel 효율성 향상의 여지)
Memory접근 효율성의 중요성

그림 1에서 for문 안의 연산을 보면 매 반복마다 곱셈, 덧셈을 위해 한번씩 global memory를 2번 접근한다. 이에 대한 global memory 접근 대비 연산의 비는 1:1 즉,1.0이다. 이 비율을 CGMA라 한다.
CGMA는 해당 cuda kernel의 성능에 많은 것을 암시하는데, 예를들어 GPU의 global memory bandwidth가 86.4GB/s라면 우리가 얻을 수 있는 가장 높은 처리량은 input data가 global memory에 적재되는 속도에 의해 제한될 것이다. data당 4byte라 했을때 21.6GB/s이상의 data는 적재할 수 없다. 이 kernel의 성능을 높이기 위해서는 CGMA를 더 높여야한다.
이를 위해 몇 가지 memory 종류를 지원한다.

Register & Shared memory
- on chip memory로써 여기 위치하는 변수는 병렬적으로 매우 빠르게 접근 가능하다.
- Register들은 각각의 thread들에게 할당되는데, 각 thread들은 자신의 register만 접근 가능하다.
- kernel function은 각 thread가 자신만의 빈번하게 사용되는 변수를 담는데 register를 이용한다.
- shared memory는 thread block에 할당되며, thread block의 모든 thread는 shared memory에 위치한 변수들에 접근할 수 있다. thread들이 input data와 그 중간 결과를 공유함으로써 효율성이 증가할 것이다.

- 변수의 범위는 그 변수를 접근할 수 있는 thread들을 명확히 한다. thread전용이라면 각 thread마다 고유한 버전이 생성되고, 각 thread는 그 변수에 대한 자신의 고유 버전만을 접근할 수 있다.
- kernel function, device function안에서 생성된 모든 자동 스칼라 변수는 Register에 위치한다.
- 변수 선언에 __shared__ keyword를 선행할때, 변수는 shared memory에 위친한다.
global memory의 통신량을 줄이기위한 전략
global memory는 큰 대신 느리고, shared memory는 작은 대신 빠르다. 흔히 사용되는 전량이 data를 tile이라고 부르는 subset들로 분할해서 tile이 shared memory에 들어가도록한다. 이때 주의 할점은 서로 다른 tile에 대한 계산이 독립적으로 수행될 수 있어야 한다.
여러 개의 block들을 사용한 행렬 곱의 예)

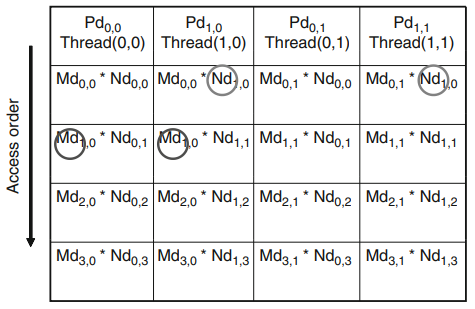
Pd를 계산하기위해 4개의 block을 사용한다고 가정하자. 그림4의 왼쪽 그림은 block(0,0)에 속하는 4개의 thread들의 수행을 강조해서 보여준다.(4개의 thread는 각각 Pd(0,0)~Pd(1,1) 계산) 그림 4의 오른쪽 그림은 block(0,0)의 모든 thread들에 의해 접근되는 모습을 보이고 있다. 각 thread는 수행 중 Md우너소 4개와 Nd원소 4개를 접근하는데, 4개의 thread들이 접근하는 Md, Nd운소가 상당히 많이 중복되는 것을 알 수있다.
현재 kernel에서는 thread(0,0), thread(1,0)모두 Md의 행 0번째 속하는 원소들을 global memory에서 읽도록 작성되어있다. 두 개의 thread들을 어떤 형태로는 협력해서 이 Md원소들을 global memory에서 한 번만 읽어올 수 있도록하면 global memory에 대한 전체 접근횟수를 절반으로 줄일 수 있을 거이다.
기본적인 idea는 thread들이 내적 계산을 위해 원소들을 개별적으로 사용하기 앞서 Md, Nd를 shared memory로 읽어노는 것이다.(capacity 주의)

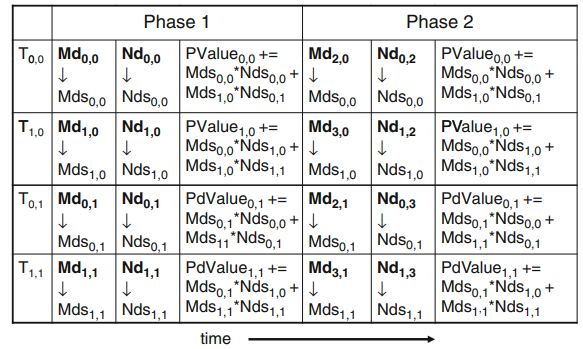
그림 5의 왼쪽 그림을 보면 Md, Nd가 2*2크기의 tile로 쪼개짐을 알 수 있다. 이제 각 thread는 내적을 사용할때 단계별로 실행한다. 매 단계마다 한 block의 모든 thread들은 Md tile한개와 Nd tile한개를 shared memory에 적재한다. 한 Blcok에 속한 각 thread가 하나의 Nd원소와 하나의 Md원소를 shared memory에서 읽어온 후, 이 요소들은 내적을 계산하기위해 사용된다.
예를들어 thread(1,1)에 의해 load된 Mds(1,1)은 therad(0,1), (1,1)에서 사용된다(1단계). 이렇게 global memory의 값을 shared memory에 load해 재사용해 global memory에 대한 access횟수를 줄일 수 있으며, 이 경우는 절반으로 줄어(tile size : 2*2)들며, tile의 크기가 N*N일때 N배 감소할 것이다.
내적 계산은 2단계로 구성되며, 일반적으로 input matrix의 차수가 N이고 tile의 차수가 tile_width라면 N/tile_width 단계로 내적계산된다.
Mds, Nds는 입력값들을 저장할때 재활용된다. 각 단계마다 input matrix의 작은 부분집합에만 집중할 수 있다.
다음은 global memory의 접근을 줄이기 위해 shared memory를 사용하는 tile 분할된 방식의 kernel함수이다.


[노란 부분]
Mds, Nds를 shared memory 변수로 선언(범위는 한 block) 하나의 block의 thread들은 동일한 Mds,Nds배열에 접근한다.
[초록 부분]
이 값들은 자동변수에 저장된다. 따라서 빠른 접근을 위해 Register에 저장된다.(범위는 각 thread) tx,ty,bx,by의 고유한 verison이 runtime system에 의해 각 thread마다 생긴다.
[파랑 부분]
thread가 생성하는 Pd원소의 row, col index를 나타낸다. bx*TILE_WIDTH+ty로 계산되는 이유는 한 Blcok이 x축으로 TILE_WIDTH의 원소를 가지고 있기 때문이다. 예를들어 block(0,1)의 thread(1,0)에 의해 계산되는 Pd원소의 x index는 0*2+1 = 1이며, y index는 1*2+0=2이다. 즉, Pd(1,2)원소가 해당 thread에 의해 계산된다.
[빨간 부분]
최종적인 Pd원소를 계산하기위해 모든 단계(phase)를 반복하는 loop이다.
[9~10번째 라인]
각 단계마다 적절한 Md,Nd원소들이 shared memory에 적재된다. 각 block은 TILE_WIDTH의 제곱만큼의 Md,Nd원소가 shared memory에 올라간다. 이때 각 thread가 적재해야하는 한개의 Md원소만 정해주면 된다. 이것은 blockIdx,threadIdx를 이용하면 편한데, 각 단계마다 적재해야하는 Md원소의 시작 index는 m*TILE_WIDTH이다. 모든 thread들이 threadIdx값에 의해 계산되는 위치로부터 한 개의 원소를 가져온다.
[11번째 라인]
barrier synchronize 함수 호출로 동일한 block의 모든 thread들이 Md, Nd tile을 Mds,Nds로 모두 적재했음을 보장한다.
'Computer Architecture > GPU' 카테고리의 다른 글
| [CUDA] 성능 고려 사항 (1) | 2022.10.29 |
|---|---|
| [CUDA] 병렬성의 제약조건 (0) | 2022.10.29 |
| [CUDA] Thread할당 (0) | 2022.10.29 |
| [CUDA] 기초 (0) | 2022.10.29 |
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[CUDA] 성능 고려 사항](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbMILa7%2FbtrPPMy6KOz%2FAAAAAAAAAAAAAAAAAAAAAAFq00v8gZpJaYENT4Dz1nlVy585914-ZWBT5C6qmRJ9%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3DA1ouoOHIK5KU0iNqZZ9VOCu3qvA%253D)
![[CUDA] Thread할당](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbsBQVU%2FbtrPP7CJcjY%2FAAAAAAAAAAAAAAAAAAAAANoQ1UbtcgzE17izihbL671lBHEuw6BcuJh1D4VfqKSd%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3Dumj8oxtL1XXJUZz2bpC54BHo1I8%253D)
![[CUDA] 기초](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbZQgW2%2FbtrPP8g9WEy%2FAAAAAAAAAAAAAAAAAAAAACbA-743tPyIOyvxp2In22pl5lNwwXAGoMoyVScRehyL%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3D5NsItB1%252B2emVabpZFYB7f04Tx24%253D)