![[CUDA] 성능 고려 사항](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbMILa7%2FbtrPPMy6KOz%2FAAAAAAAAAAAAAAAAAAAAAAFq00v8gZpJaYENT4Dz1nlVy585914-ZWBT5C6qmRJ9%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3DA1ouoOHIK5KU0iNqZZ9VOCu3qvA%253D)

CUDA kernel이 어떤 종류의 device에서도 올바르게 동작할 수 있지만, 수행 속에서도 각 device의 제약에따라 크게 다를 수 있다. 본 단원에서는 CUDA device의 주요 제약을 논하고 어떤 해결방법이 있는지 알아본다.
thread 수행
kernel이 수행되면 두 수준 계층으로 구성되는 thread들의 집합인 grid가 생성된다. grid는 1,2차원 배열들의 block으로 구성되며, block은 1,2,3차원 배열들의 thread로 구성되었다. 한 block은 다른 block과 상관없이 어떤 순서로든 수행할 수 있어 CUDA의 투명확장성을 가능하게 한다.
block내 thread들도 서로 상관없이 어떤 순서로도 수행될 수 있다.(순서에 상관이 있다면 barrier동기화) cuda device의 여러 hardware 비용으로 인해 cuda device는 여러개의 thread를 묶어서 수행한다.(때때로 이러한 전략이 특정 kernel의 성능 제약으로 발생할 수 있다.)
각 block은 warp로 분할되는데, 각 warp는 32개의 thread로 구성되며, warp를 분할때는 threadIdx로 분할한다. 그림 1은 T(0,0)부터 T(3,3)까지의 16개의 thread가 warp의 절반을 채울 것이다.

Hardware는 다음 명령어를 수행하기 전, 동일한 warp내 모든 thread들에 대해서 현재 명령어를 수행한다. SIMT라 불리는데 이는 hardware 비용 제약 때문에 고안되었다. 여러 개의 thread가 연산을 분담하으로써 하나의 명령어를 처리하는 비용이 줄어들기 때문이다. 한 warp내 모든 thread들이 data를 처리할때 똑같은 제어 흐름 경로를 따른다면 문제가 없지만, 다른 제어 흐름을 가진다면 더 이상 SIMT구조가 효율적이지 않다.

그림 2와 같은 상황에서 분기된 경로들 때문에 여러 단계가 필요하다. if then단계를 따르는 thread들, else 경로를 따르는 thread를 위해서 필요하다. 이 단계들은 순차적이기에 지연시간이 증가한다.
Reduction 알고리즘의 예)

그림2의 예는 배열에서 하나의 값을 추출하며, 모든 원소를 방문하면 종료된다. 하지만 배열의 원소가 많아지면 문제가 발생한다. 원래 배열은 global memory에 있다. 각 thread들은 배열의 각 구획에 대한 reduction을 수행하는데 먼저 해당 원소를 shared memory로 적재한 뒤, 병렬 reduction을 수행한다.
위 kernel은 thread분기를 내포하는데, loop의 첫번째 반복동안 threadIdx.x가 짝수인 thread들만 더하기 구문을 수행한다. 이 thread들을 수행하는데 한 단계가 필요하고, 추가적인 단계가 8번째 라인을 수행하지 않는 thread들을 위해 필요하다.
이를 해결하기 위해 그림 3과 같이 약간 다른 알고리즘을 사용해보자.

마찬가지로 loop안에 if문을 가지고 있지만 성능차이는 확연하다. warp는 연속된 threadIdx값을 가지기 때문에 각 iteration에서 초반의 연속된 warp들은 더하기 구문을 실행하는 반면, 후반의 warp들은 더하기 구문을 아예 실행하지 않는다. 즉, warp내의 모든 thread들이 동일한 경로를 따른다. (하지만 완전히 분기를 제거하지는 않는데, 5번째 반복부터는 8행을 수행하는 thread가 32보다 작아지기 때문이다.)
global memory bandwidth
global memory로부터 shared memory와 register에 data를 효율적으로 이동시키는 메모리 병합 기술에 대해 살펴보자.
DRAM에 대한 접근이 길게 연속된 위치에 대해서 이루어지도록 kernel의 data접근 조정이 필요하다. 즉, programmer가 DRAM구조를 잘 파악해 thread들이 memory 접근에 유리한 패턴으로 구성해야된다.
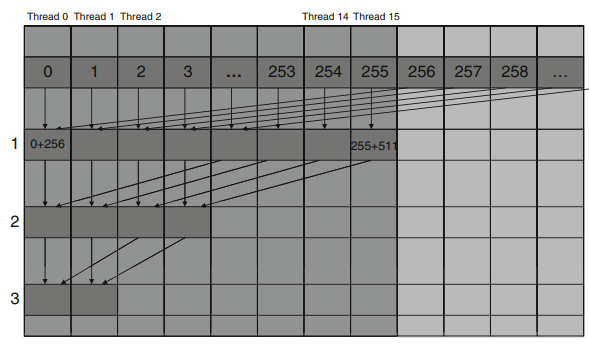
이 기술은 warp내 모든 thread들이 어떤 시점에서든지 동일한 명령어를 수행한다는 것을 이용한다. 즉, 가장 유리한 접근 패턴은 동일한 명령어에 대해 warp내 모든 thread들이 연속적인 global memory에 위치해 있을때이다. 이럴경우 hardware는 이 접근을 하나로 묶어서 연속된 DRAM위치에 대한 하나의 통합된 접근을 만든다. 그림 4는 memory병합 측면에서 유불리한 접근 pattern을 보이고 있다.
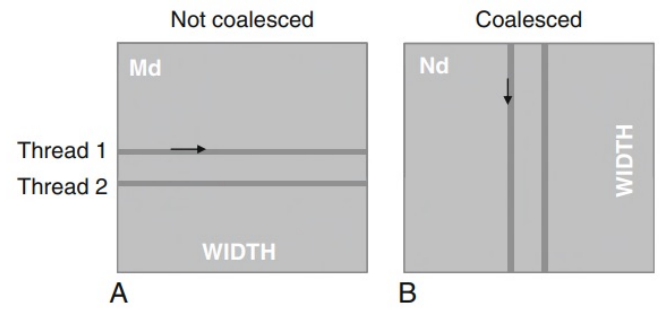
불리 : warp내 thread들이 각 행의 동일 열을 읽을 때
유리 : warp내 thread들이 각 열의 동일 행을 읽을 때
이를 address mapping관점에서 보면 그림5와 같다.


행렬 곱셈의 예)


[9~10 line]
Md와 Nd행렬에 대해 각각의 tile을 shared memory에 적재.
타일링으로 인해 메모리 병합에 불리한 데이터 패턴이라도 그것에 대한 불이익은 없다.
SM자원의 동적 분할
SM의 실행자원은 register, thread block, thread slot을 포함한다. 이 자원들은 동적으로 분할되고, thread에 할당되어 그 수행에 사용된다. Fermi architecture에서 1536개의 thread slot을 가지는데 이 slot은 분할되어 런타임에 thread blcok에 할당된다. 만약 각 block이 512thread로 구성한다면 SM은 thread slot의 제약으로 인해 3개의 blcok을 수용한다.
thread block간 동적으로 thread slot을 분할할 수 있는 기능 때문에 SM은 다양하게 사용될 수 있다. 하지만 자원의 동적분할은 자원 제약간에 미묘한 상호작용을 초래해 자원을 충분히 활용하지 못하는 상황이 일어난다. 예를들어 blcok이 128thread를 가진다면, 1536개의 thread slot은 12개의 block으로 분할되어 할당되어야하지만 각 SM당 8개의 blcok만 수용 가능하기에 나머지 4개는 수용할 수 없는 일이 발생한다.
Register file은 동적으로 분할되는 자원이다. cuda kernel에서 선언된 자동변수들이 register에 위치한다. 따라서 kernel별 register의 필요가 다 다르다. SM은 적은 수의 register들이 필요한 경우에는 더 많은 block을 수용하고, register가 더 많이 필요하면 blcok수를 줄인다.
행렬 곱의 예)
그림 7은 자원 제약의 예를 보여준다. kernel code가 thread당 10개의 register들을 상용한다고 가정하고, 16*16으로 구성된 thread block을 사용한다면 각 SM당 수행되는 thread 수는 얼마나 되는가?
1. 각 thread block마다 필요한 register는 10*16*16 = 2560.
2. 3개의 block에서 필요한 register는 3*2560 = 7680 < 8192 (OK)

만약 각 thread별 사용되는 register의 수가 11개로 증가한다면?
11*16*16 = 8448 > 8192(제약 발생) B와 같이 SM은 block의 개수를 하나 줄임으로써 처리하는데 이때 필요한 register수는 5632가 되고 이것은 SM에서 수행되는 thread 수를 512로 줄인다. 이를 performace cliff이라 한다.
Data prefetching
일반적으로 병렬 컴퓨팅에서 가장 중요한 자원 제약 중의 하나는 전역 메모리가 데이터 접근에대해서 제한된 대역폭을 가진다는 점과 이 접근들이 완료되는데 오랜시간이 걸린다는 문제이다. CUDA의 threading 모델에서는 warp들이 메모리 접근에 대한 결과를 기다리는 동안 다른 warp들이 수행을 진행할 수 있도록 함으로써 긴 메모리 접근 지연 시간을 감내한다. 이것은 매우 좋지만 모든 thread들이 접근 결과를 기다리는 경우에는 충분하지 않을 것이다.
이 문제에 대한 유용하면서 보완적인 해결책은 현재 데이터 원소를 소비하는 동안 다음 데이터 원소를 미리 가져오는 것인데, 이렇게 하면 메모리 접근과 데이터 소비 사이에 독립적이 명령어의 수를 늘리게 된다. prefetch기법은 흔히 tiling과 함께 사용되어 제한된 대역폭과 긴 지연시간의 문제를 동시에 해결한다.
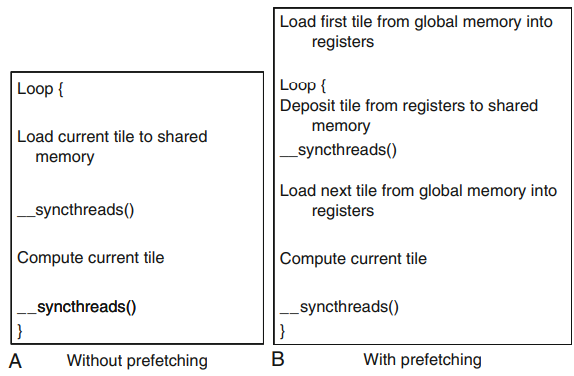
그림 8의 A는 tiling에 대한 행렬곱셈 커널에 해당한다. 사실 데이터를 전역 메모리 위치에서 shared memory로 옮기는 과정은 2개의 부분으로 나뉜다. 첫 번째 부분은 global memory에서 register로 옮기는 것이고, 두 번째 부분은 register에서 shared memory에 저장한다. 이 두 부분 사이에는 독립적인 명령어가 없다. 현재 tile을 적재하는 warp들은 현재 tile을 계산하기 전 긴 시간을 기다리게 될 가능성이 높다.
그림 B는 prefetch버전이다. loop에 들어가기 전에 먼저 첫 번째 타일을 register에 적재한다. loop에 일단 들어가면 적재된 데이터를 shared memory로 옮긴다. block의 모든 thread들이 데이터를 올려놓으면 다음 tile을 register에 적재하기 시작한다. 여기서 비결은 적재된 다음 tile 데이터가 바로 연산에 소비되지 않는다는 점이다.
공유 메모리의 크기를 두 배 더 많이 사용하는 것과 별도로 데이터 prefetch는 추가적인 자동변수(레지스터)를 두 개 더 사용한다.
'Computer Architecture > GPU' 카테고리의 다른 글
| [CUDA] 병렬성의 제약조건 (0) | 2022.10.29 |
|---|---|
| [CUDA] CUDA Memory (0) | 2022.10.29 |
| [CUDA] Thread할당 (0) | 2022.10.29 |
| [CUDA] 기초 (0) | 2022.10.29 |
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[CUDA] CUDA Memory](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fci2YZu%2FbtrPPOQW8wd%2FAAAAAAAAAAAAAAAAAAAAAHkBpyDiG62tDjHcROYPPapvGlT0fdIistAXJMjWm7ee%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3DTnEu62T3Je5hjIjoQPAJyFt5Xe8%253D)
![[CUDA] Thread할당](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbsBQVU%2FbtrPP7CJcjY%2FAAAAAAAAAAAAAAAAAAAAANoQ1UbtcgzE17izihbL671lBHEuw6BcuJh1D4VfqKSd%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3Dumj8oxtL1XXJUZz2bpC54BHo1I8%253D)
![[CUDA] 기초](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbZQgW2%2FbtrPP8g9WEy%2FAAAAAAAAAAAAAAAAAAAAACbA-743tPyIOyvxp2In22pl5lNwwXAGoMoyVScRehyL%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3D5NsItB1%252B2emVabpZFYB7f04Tx24%253D)