

사이킷런으로 타이타닉 생존자 예측DNN/머신러닝2021. 6. 23. 21:42
Table of Contents
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
titanic_df = pd.read_csv('./train.csv')
titanic_df.head()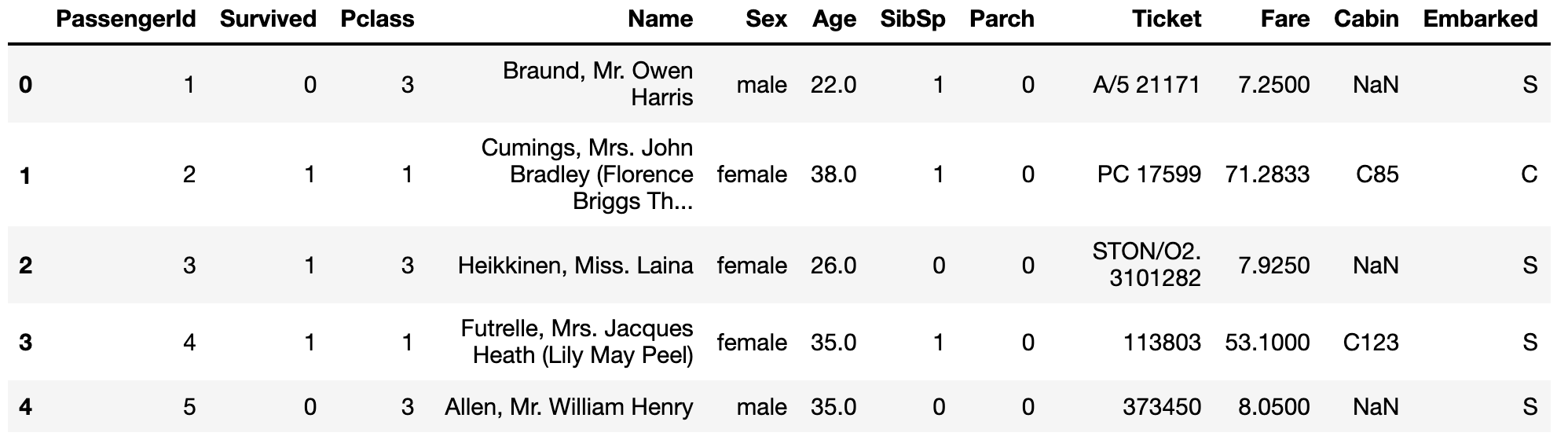
info() 메소드를 사용해 결측치를 확인해 본다.
titanic_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
fillna()메소드를 이용해 결측치를 채운다.
titanic_df['Age'].fillna(titanic_df['Age'].mean(),inplace=True)
titanic_df['Cabin'].fillna('N',inplace=True)
titanic_df['Embarked'].fillna('N',inplace=True)groupby를 이용해 성별과 생존여부의 관계를 알아보았다.
titanic_df.groupby(['Sex','Survived'])["Survived"].count()
Sex Survived
female 0 81
1 233
male 0 468
1 109
Name: Survived, dtype: int64
sns.barplot(x='Sex',y='Survived',data=titanic_df)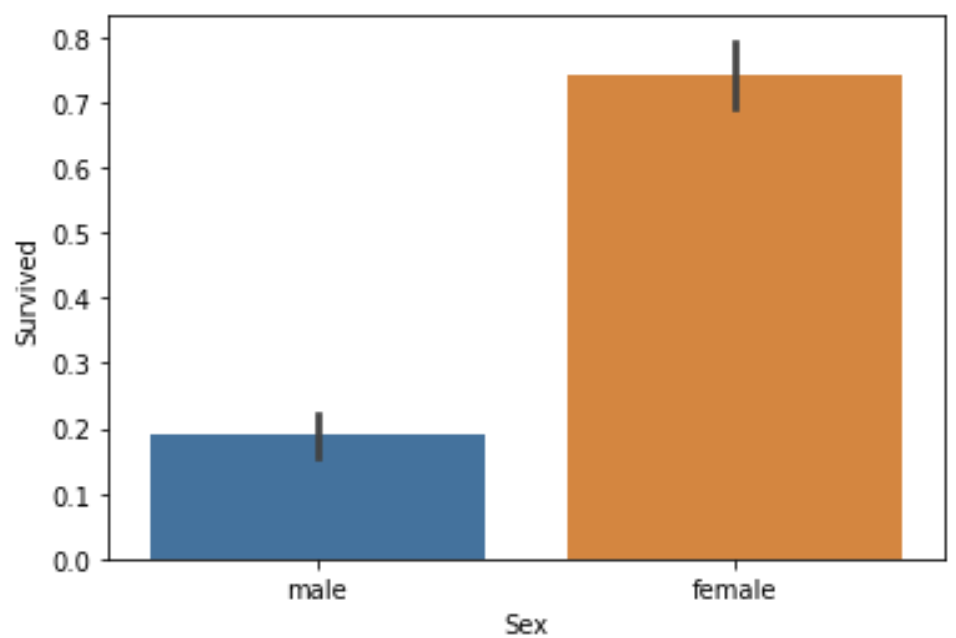
이번에는 Pclass와 생존여부를 barplot으로 그려보겠습니다.
sns.barplot(x='Pclass',y='Survived',hue='Sex',data=titanic_df)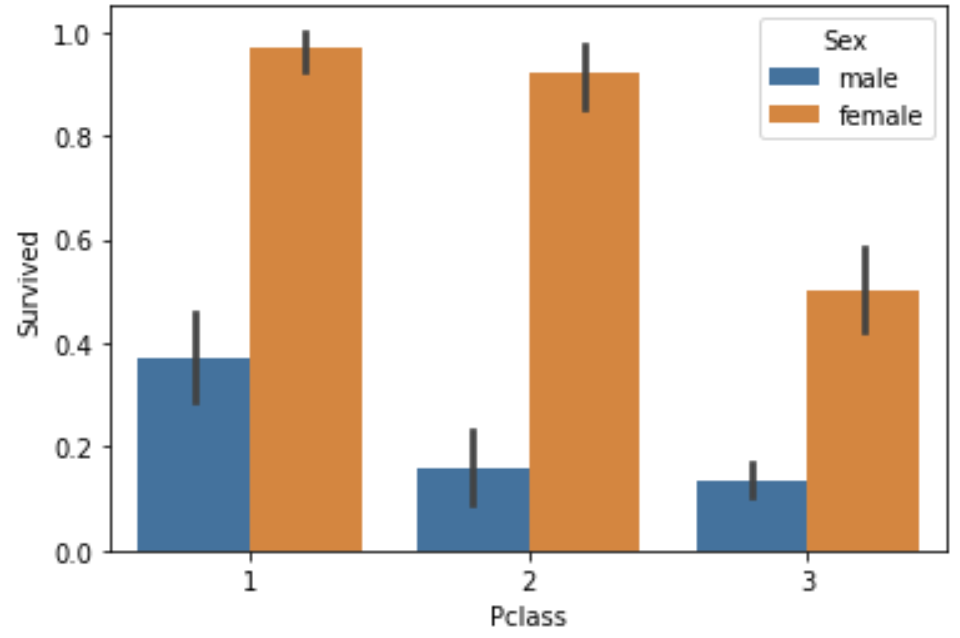
Cabin , Sex , Embarked 문자열로 이루어진 피처들의 one-hot-encoding
from sklearn import preprocessing
def encode_features(dataDF):
features = ['Cabin','Sex','Embarked']
for feature in features:
le = preprocessing.LabelEncoder()
le =le.fit(dataDF[feature])
dataDF[feature] = le.transform(dataDF[feature])
return dataDF
titanic_df = encode_features(titanic_df)
titanic_df.head()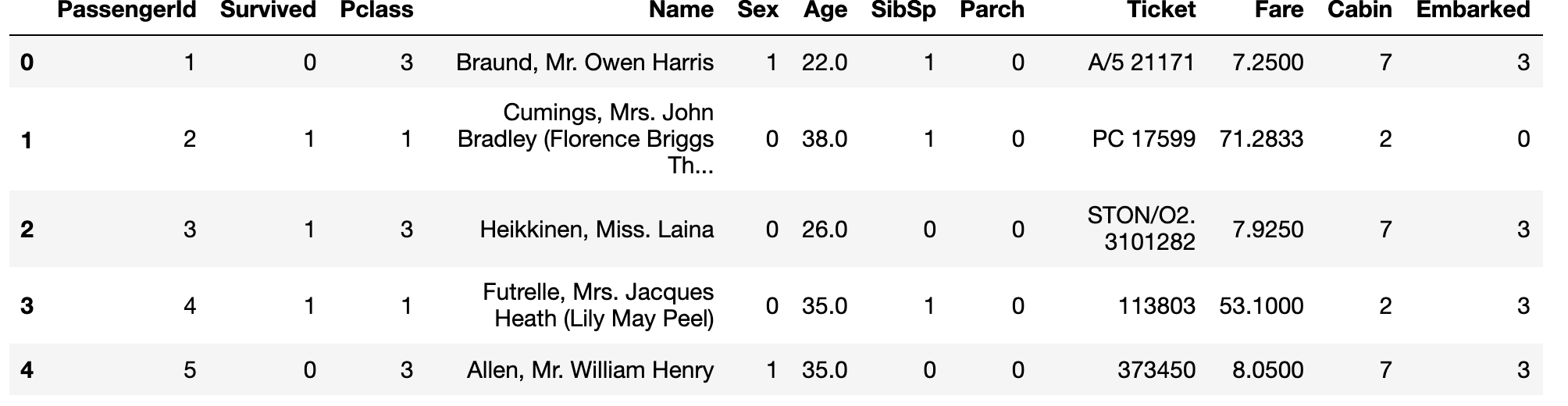
이때까지 했던 작업을 함수로 만들어보고 바로 학습/예측/평가를 해보겠습니다.
def fillna(df):
df["Age"].fillna(df["Age"].mean(),inplace=True)
df["Cabin"].fillna('N',inplace = True)
df["Embarked"].fillna('N',inplace=True)
df["Fare"].fillna(0,inplace=True)
return df
def drop_feature(df):
df.drop(["PassengerId","Name","Ticket"],axis=1,inplace=True)
return df
def format_feature(df):
df["Cabin"] = df["Cabin"].str[:1]
features = ["Cabin","Sex","Embarked"]
for feature in features:
le = preprocessing.LabelEncoder()
le = le.fit(df[feature])
df[feature] = le.transform(df[feature])
return df
def transform_features(df):
df = fillna(df)
df = drop_feature(df)
df = format_feature(df)
return df
#데이터 가공
titanic_df = pd.read_csv("./train.csv")
y_titanic_df = titanic_df['Survived']
X_titanic_df = titanic_df.drop('Survived',axis=1)
X_titanic_df = transform_features(X_titanic_df)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X_titanic_df,y_titanic_df,test_size=0.2,random_state=11)
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
dt_clf = DecisionTreeClassifier(random_state=11)
rf_clf = RandomForestClassifier(random_state=11)
lr_clf = LogisticRegression()
#DecisionTreeClassifier 학습/예측/평가
dt_clf.fit(X_train,y_train)
dt_pred = dt_clf.predict(X_test)
print("DecisionTreeClassifier 정확도 :{:.4f}".format(accuracy_score(y_test,dt_pred)))
#RandomForestClassifier 학습/예측/평가
rf_clf.fit(X_train,y_train)
rf_pred = rf_clf.predict(X_test)
print("RandomForestClassifier 정확도 : {:.4f}".format(accuracy_score(y_test,rf_pred)))
#LogisticRegression 학습/예측/평가
lr_clf.fit(X_train,y_train)
lr_pred = lr_clf.predict(X_test)
print("LogisticRegression 정확도 : {:.4f}".format(accuracy_score(y_test,lr_pred)))
DecisionTreeClassifier 정확도 :0.7877
RandomForestClassifier 정확도 : 0.8547
LogisticRegression 정확도 : 0.8492검증.
1. kfold
2. cross_val_score()
from sklearn.model_selection import KFold
def exec_kfold(clf,folds=5):
kfold = KFold(n_splits=folds)
scores = []
for iter_count , (train_index,test_index) in enumerate(kfold.split(X_titanic_df)):
#kfold.split 함수는 학습용,검증용 데이터를 row index 반환
X_train,X_test = X_titanic_df.values[train_index],X_titanic_df.values[test_index]
y_train,y_test = y_titanic_df.values[train_index],y_titanic_df.values[test_index]
#Classifier 학습/예측 정확도 계산
clf.fit(X_train,y_train)
predictions = clf.predict(X_test)
accuracy = accuracy_score(y_test,predictions)
scores.append(accuracy)
print("교차 검증 {} 정확도 : {:.4f}".format(iter_count,accuracy))
mean_score = np.mean(scores)
print("평균 정확도:{0:.4f}".format(mean_score))
#exec_kfold 호출
exec_kfold(dt_clf,folds=5)
교차 검증 0 정확도 : 0.7542
교차 검증 1 정확도 : 0.7809
교차 검증 2 정확도 : 0.7865
교차 검증 3 정확도 : 0.7697
교차 검증 4 정확도 : 0.8202
평균 정확도:0.7823
from sklearn.model_selection import cross_val_score
scores = cross_val_score(dt_clf,X_titanic_df,y_titanic_df,cv=5)
for iter_count , accuracy in enumerate(scores):
print("교차검증 {} 정확도 : {:.4f}".format(iter_count,accuracy))
print("평균 정확도 : {:.4f}".format(np.mean(scores)))
교차검증 0 정확도 : 0.7430
교차검증 1 정확도 : 0.7753
교차검증 2 정확도 : 0.7921
교차검증 3 정확도 : 0.7865
교차검증 4 정확도 : 0.8427
평균 정확도 : 0.7879GridSearchCV를 이용해 DecisionTreeClassifier의 최적 하이퍼 파라미터를 찾아 보자.
from sklearn.model_selection import GridSearchCV
parameters = {'max_depth':[2,3,5,10],'min_samples_split':[2,3,5],'min_samples_leaf':[1,5,8]}
grid_dclf = GridSearchCV(dt_clf,param_grid = parameters,scoring='accuracy',cv=5)
grid_dclf.fit(X_train,y_train)
print("GridSearchCV 최적 하이퍼 파라미터 :",grid_dclf.best_params_)
print("GridSearchCV 최고 정확도 :",grid_dclf.best_score_)
best_dclf = grid_dclf.best_estimator_
dpredictions = best_dclf.predict(X_test)
accuracy = accuracy_score(y_test,dpredictions)
print("테스트 세트에서의 DecisionTreeClassifier 정확도:{:.4f}".format(accuracy))
GridSearchCV 최적 하이퍼 파라미터 : {'max_depth': 3, 'min_samples_leaf': 5, 'min_samples_split': 2}
GridSearchCV 최고 정확도 : 0.7991825076332119
테스트 세트에서의 DecisionTreeClassifier 정확도:0.8715'DNN > 머신러닝' 카테고리의 다른 글
| 분류 - Ensemble(앙상블) [결정트리,RandomForest,Boost,스태킹] (0) | 2021.07.21 |
|---|---|
| 성능지표 / 평가 (0) | 2021.06.25 |
| 붓꽃 품종 예측 , 사이킷런 , Model Selection , 데이터 전처리 (0) | 2021.06.23 |
| Pandas (0) | 2021.06.22 |
| Numpy(넘파이) (0) | 2021.06.22 |
@Return :: Return
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![분류 - Ensemble(앙상블) [결정트리,RandomForest,Boost,스태킹]](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbDjxle%2FbtradRTnr3Q%2FAAAAAAAAAAAAAAAAAAAAAGSBGwLNREfxfM-kxnNWCQVuM7J6TjxVjlKNO80zn9Uq%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3DfO1sG6%252FgBRFJ1AXWWhWJ8qNsICI%253D)


