

numpy는 리스트와 비슷합니다. 하지만 왜 리스트를 쓰지 않을가요?
넘파이는 다차원 배열을 좀 더 효율적으로 다룰 수 있고 C로 구현되어있어 list보다 빠른 속도를 가지고 있기 때문입니다.
또한 라이브러리에 구현되어있는 함수들을 이용해 짧고 간결한 코드를 작성할수 있다는 장점을 가지고 있습니다.!
-실습
1차원,2차원 배열을 생성해보겠습니다.
import numpy as np
array1 = np.array([1,2,3])
array2 = np.array([[1,2,3]])
print(array1)
print(array2)
type(array1)
#[1 2 3]
#[[1 2 3]]
#numpy.ndarrayarray1 과 array2의 차이는 무엇일까요? 1차원 배열인 array1는 3개의 데이터를 가지고 있는 반면 2차원 array2는 하나의 row , 3개의 column을 가지고 있습니다.(1행3열)
*ndarray의 데이터 타입
연산의 특성상 같은 데이터 타입만 가능 합니다. list와 비교해보면 ,
list1 =['test',True,1]
print(type(list1))array1 = np.array(list1)
print(type(array1))
print(array1,array1.dtype)
출력 결과를 보면 모두 문자형 값으로 변환되어 출력된것을 알 수있습니다. 넘파이에서는 여러 데이터 타입이 섞여 있을 경우 큰 data type으로 자동으로 바꿔줍니다. 또한 astype()메소드를 이용해 자신이 원하는 데이터로도 변경이 가능하지요.
이제 본견적으로 ndarray를 생성해보겠습니다.
a1 = np.arange(10) #arange([start,] stop[, step,], dtype=None) (for문과 동일)
print(a1)
print(a1.shape)
[0 1 2 3 4 5 6 7 8 9]
(10,)array가 모두 0으로 이루어진 array도 zeros()를 이용해 만들 수있습니다.
zero_array = np.zeros((3,3),dtype='int32') #zeros(shape, dtype=float, order='C')
print(zero_array)
[[0 0 0]
[0 0 0]
[0 0 0]]0으로도 했으면 1로도 만들수 있겠죠?
one_array = np.ones((3,3)) #zeros(shape, dtype=float, order='C')
print(one_array)
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]이 뿐만 아니라 원하는 size 와 원하는 숫자를 직접 지정해줄 수 있습니다.
np.full((2,2),7)
array([[7, 7],
[7, 7]])이제 이렇게 만든 array의 shape을 수정하는 방법에 대해서 알아 보겠습니다.
일단 array를 하나 생성하고,
x = np.arange(1,16)
print(x)
print(x.shape)
[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
(15,)reshape() 메소드를 이용해 원하는 shape으로 변경 할 수 있습니다.
x1=x.reshape(5,3)
x1
array([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12],
[13, 14, 15]])
x2 = x.reshape(5,-1) #-1 알아서 결정
x2
array([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12],
[13, 14, 15]])여기서 좀더 나아가서 reshape() 메소드의 파라미터중 order에 대해서 알아보겠습니다.
order='C'(디폴트):왼족에서 오른쪽 순으로 원소를 넣는다.
order='F' :위에서 아래 순으로 원소를 넣는다. 설명 을 돕기 위해 사진을 첨부 하였습니다.
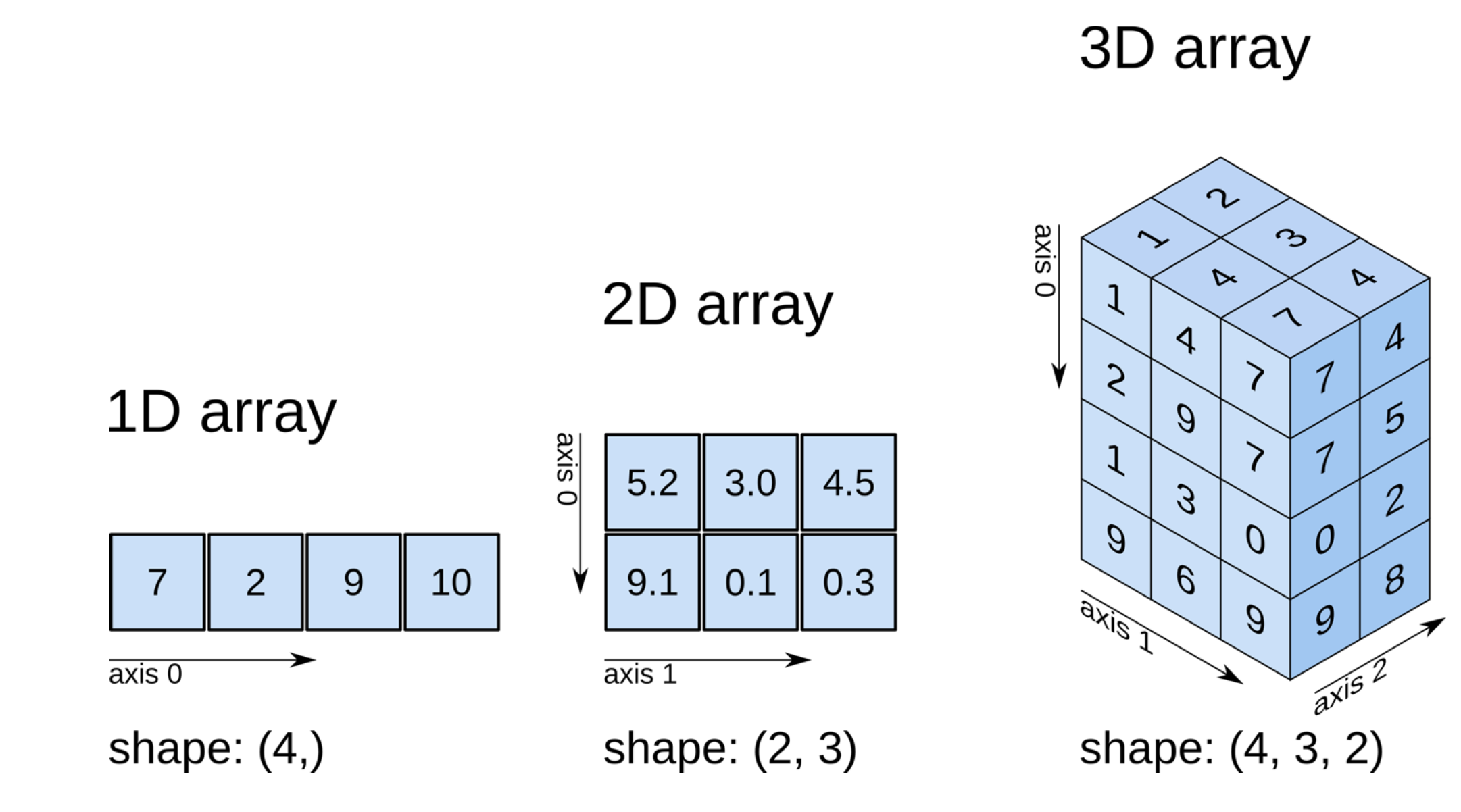
y = np.arange(12).reshape((2,3,2),order='C')
y
array([[[ 0, 1],
[ 2, 3],
[ 4, 5]],
[[ 6, 7],
[ 8, 9],
[10, 11]]])
z = np.arange(12).reshape((2,3,2),order = 'F')
z
array([[[ 0, 6],
[ 2, 8],
[ 4, 10]],
[[ 1, 7],
[ 3, 9],
[ 5, 11]]])ravel()메소드를 활용하면 다차원 배열을 1차원 배열로 변경할 수 있습니다.
'order' 파라미터
'C' : row 우선 변경
'F' : column 우선 변경
x = np.arange(15).reshape(3,5)
print(x)
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
np.ravel(x,order='C')
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]ravel 메소드와 똑같이 flatten 메소드 또한 다차원 배열을 1차원으로 변경할 수있습니다. 다만 flatten메소드는 ravel과 달리 copy 즉, 원본 데이터가 아닌 복사본을 반환 합니다.
'order' 파라미터
'C' : row 우선 변경
'F' : column 우선 변경
y = np.arange(15).reshape(3,5)
print(y)
y2 = y.flatten(order='F')
y2
array([ 0, 5, 10, 1, 6, 11, 2, 7, 12, 3, 8, 13, 4, 9, 14])*axis 이해하기
몇몇 함수에는 axis 파라미터가 존재 합니다.
axis값이 없는 경우에는 전체 데이터에 적용하고, axis값이 있는 경우에는 해당axis를 따라서 연산을 적용합니다.
sum()메소드를 이용해 axis의 개념을 이해해 보도록 하겠습니다. 바로 위에 올려둔 넘파이 축에 관련된 사진을 참고해주세요!
x = np.arange(15)
print(x)
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
#1차원 데이터에 적용
np.sum(x,axis=0)
105#행렬에 적용
y = x.reshape(3,5)
print(y)
k =np.sum(y,axis=0)
print(k)
np.sum(k)
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
[15 18 21 24 27]
105np.sum(y, axis=1)
array([10, 35, 60])#3차원 텐서에 적용
z = np.arange(36).reshape(3, 4, 3)
print(z)
[[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
[[12 13 14]
[15 16 17]
[18 19 20]
[21 22 23]]
[[24 25 26]
[27 28 29]
[30 31 32]
[33 34 35]]]
np.sum(z, axis=0)
array([[36, 39, 42],
[45, 48, 51],
[54, 57, 60],
[63, 66, 69]])
마지막 3차원 텐서에 axis를 적용하는게 약간 헷갈리수 있습니다.! 약간의 tip을 드리자면 위 사진을 참고해서 축의 방향으로 찌부? 압축한다! 라고 생각하시면 조금 더 이해하기 편했습니다. ㅎ
*Indexing
축을 이해했다면 자유자재로 각 차원의 인덱스에 접근 할 수 있습니다.
이번에도 각 차원별로 인덱싱하는 과정을 살펴 보겠습니다.
# 1차원 벡터 인덱싱
x = np.arange(10)
print(x)
x[3]=100
print(x)
[0 1 2 3 4 5 6 7 8 9]
[ 0 1 2 100 4 5 6 7 8 9]#2차원 행렬 인덱싱
x = np.arange(10).reshape(2,5)
print(x)
x[1,1] = 100
print(x)
x[0,-1]=100
print(x)
[[0 1 2 3 4]
[5 6 7 8 9]]
[[ 0 1 2 3 4]
[ 5 100 7 8 9]]
[[ 0 1 2 3 100]
[ 5 100 7 8 9]]#3차원 텐서 인덱싱
#Tensor : 데이터의 배열
x = np.arange(36).reshape(3,4,3)
print(x)
[[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
[[12 13 14]
[15 16 17]
[18 19 20]
[21 22 23]]
[[24 25 26]
[27 28 29]
[30 31 32]
[33 34 35]]]
x[1]
array([[12, 13, 14],
[15, 16, 17],
[18, 19, 20],
[21, 22, 23]])이제 슬라이싱을 해보겠습니다.
인덱싱과 마찬가지로 기존 list,문자열 슬라이싱과 동일한 개념입니다.
#1차원 벡터 슬라이싱
x = np.arange(10)
print(x)
[0 1 2 3 4 5 6 7 8 9]
x[1:]
array([1, 2, 3, 4, 5, 6, 7, 8, 9])#2차원 행렬 슬라이싱
x = np.arange(10).reshape(2,5)
print(x,"\n")
print(x[0:2],"\n")
print(x[1:2],"\n")
print(x[:1,:2])
[[0 1 2 3 4]
[5 6 7 8 9]]
[[0 1 2 3 4]
[5 6 7 8 9]]
[[5 6 7 8 9]]
[[0 1]]#3차원 텐서 슬라이싱
x = np.arange(54).reshape(2,9,3)
print(x)
[[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]
[12 13 14]
[15 16 17]
[18 19 20]
[21 22 23]
[24 25 26]]
[[27 28 29]
[30 31 32]
[33 34 35]
[36 37 38]
[39 40 41]
[42 43 44]
[45 46 47]
[48 49 50]
[51 52 53]]]
x[:1, :2, :]
array([[[0, 1, 2],
[3, 4, 5]]])
x[0, :2, :2]
array([[0, 1],
[3, 4]])
Boolean indexing
ndarry 인덱싱 시 , bool 리스트를 전달하여 True인 경우만 필터링.
x = np.random.randint(1,100,size=10)
print(x)
[78 39 21 1 80 38 31 97 48 90]
even_mask = x%2 ==0
print(even_mask)
[ True False False False True True False False True True]다중조건 사용하기
파이썬 논리 연산자인 and , or은 사용이 불가 합니다. & , | 와 같은 기호를 사용해야 합니다.
x1= x[(x % 2 == 0) & (x < 30)]
x1
array([], dtype=int64)
x[(x < 10) | (x > 50)]
array([78, 1, 80, 97, 90])행렬의 정렬 (sort , argsort)
sort 메소드와 argsort 메소드 모두 행렬의 정렬을 하는 기능을 합니다. 하지만 sort 메소드 같은 경우 복사본을 반환하기 때문에 원본행렬은 변하지 않습니다. 원본행렬까지 변화를 주고 싶을때 argsort 메소드를 사용하면 됩니다.
org_array = np.array([5,7,2,4])
print("원본행렬 : {}".format(org_array))
원본행렬 : [5 7 2 4]
#sort 정렬 원본행렬은 변하지 않음 > 복사본 출력
sort_array = np.sort(org_array)
print("변환된 행렬: {}".format(sort_array))
print("원본행렬 : {}".format(org_array))
변환된 행렬: [2 4 5 7]
원본행렬 : [5 7 2 4]
#argsort 정렬 원본행렬이 변한다.
argsort_array = np.argsort(org_array)
print("변환된 행렬: {}".format(argsort_array))
print("원본행렬 : {}".format(argsort_array))
변환된 행렬: [2 3 0 1]
원본행렬 : [2 3 0 1]
행렬의 계산
dot 메소드를 이용해 행렬계산을 시행합니다.
a = np.array([[1,2,3],[4,5,6]])
b = np.array([[7,8],[9,10],[10,11]])
dot_product = np.dot(a,b)
dot_product
array([[ 55, 61],
[133, 148]])
numpy의 서브 모듈
random 서브 모듈
-rand 메소드 : 0,1사이의 분포로 랜덤한 ndarray를 생성합니다.
-randn 메소드 : 정규분포로 샘플링된 랜덤 ndarray를 생성합니다.
'DNN > 머신러닝' 카테고리의 다른 글
| 성능지표 / 평가 (0) | 2021.06.25 |
|---|---|
| 사이킷런으로 타이타닉 생존자 예측 (0) | 2021.06.23 |
| 붓꽃 품종 예측 , 사이킷런 , Model Selection , 데이터 전처리 (0) | 2021.06.23 |
| Pandas (0) | 2021.06.22 |
| 차원 축소(Dimension Reduction) (0) | 2021.06.21 |
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!



