

Series
- 판다스의 기본 객체 중 하나.
- numpy의 ndarray를 기반으로 인덱싱 기능을 추가하여 1차원 배열을 나타냄.
import pandas as pd
import numpy as np
s1 = pd.Series([1,2,3]) #파이썬 enumerate 느낌
s1
0 1
1 2
2 3
s2 = pd.Series(['a','b','c'])
s2
0 a
1 b
2 c
s3 =pd.Series(np.arange(200))
s3
0 0
1 1
2 2
3 3
4 4
...
195 195
196 196
197 197
198 198
199 199다음과 같이 인덱스도 사용자 지정으로 바꿀 수 있습니다.
s4 = pd.Series([1, 2, 3], ['a', 'b', 'c'])
s4
a 1
b 2
c 3
s5 = pd.Series(np.arange(5), np.arange(100, 105), dtype=np.int16)
s5
100 0
101 1
102 2
103 3
104 4
s5.index
Int64Index([100, 101, 102, 103, 104], dtype='int64')
s5.values
array([0, 1, 2, 3, 4], dtype=int16)
Series size, shape, unique, count, value_counts 함수
- size : 개수 반환
- shape : 튜플형태로 shape반환
- unique: 유일한 값만 ndarray로 반환
- count : NaN을 제외한 개수를 반환
- mean: NaN을 제외한 평균
- value_counts: NaN을 제외하고 각 값들의 빈도를 반환
Series 값 변경
- 추가 및 업데이트: 인덱스를 이용
- 삭제: drop함수 이용
s = pd.Series(np.arange(100, 105), ['a', 'b', 'c', 'd', 'e'])
s
a 100
b 101
c 102
d 103
e 104
s.drop('a',inplace=True) #inplace =True >> 원본
b 101
c 102
d 103
e 104위 코드에서 inplace =Ture의 의미는 원본데이터에 drop을 적용하겠다는 것입니다.
이제 데이터를 불러와서 dataframe의 구성을 파악해 보도록 하겠습니다.
- shape 속성 (row, column)
- describe 함수 - 숫자형 데이터의 통계치 계산
- info 함수 - 데이터 타입, 각 아이템의 개수 등 출력
train_data.head() # head는 특정 조건이 없으면 처음부터5개의 row를 가져옵니다.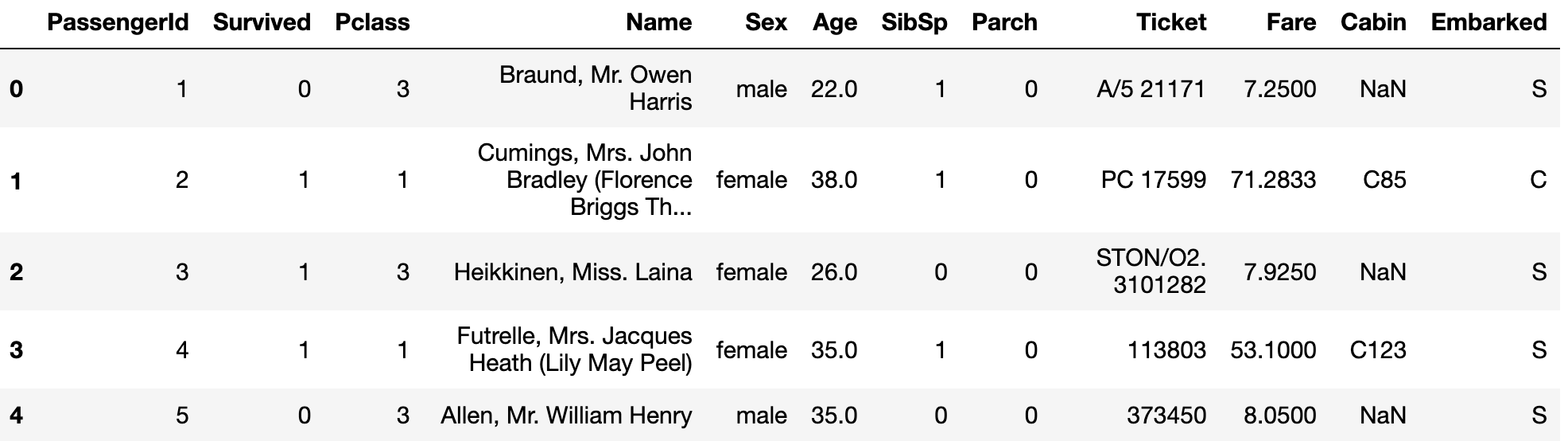
read_csv 함수 파라미터
- sep - 각 데이터 값을 구별하기 위한 구분자(separator) 설정
- header - header를 무시할 경우, None 설정
- index_col - index로 사용할 column 설정
- usecols - 실제로 dataframe에 로딩할 columns만 설정
train_data = pd.read_csv('train.csv', index_col='PassengerId', usecols=['PassengerId', 'Survived', 'Pclass', 'Name'])
train_data
dataframe slicing
-dataframe의 경우 기본적으로 []연산자가 column 선택에 사용
-하지만 , slicing은 row 레벨로 지원
train_data[7:10]
row 선택하기
- Seires의 경우 []로 row 선택이 가능하나, DataFrame의 경우는 기본적으로 column을 선택하도록 설계
- loc, .iloc로 row 선택 가능
- loc - 인덱스 자체를 사용
- iloc - 0 based index로 사용
- 이 두 함수는 ' , '를 사용하여 column 선택도 가능
train_data.loc[891]
Survived 0
Pclass 3
Name Dooley, Mr. Patrick
Name: 891, dtype: objecttrain_data.iloc[[0, 100, 200, 2]]
Survived Pclass Name
PassengerId
1 0 3 Braund, Mr. Owen Harris
101 0 3 Petranec, Miss. Matilda
201 0 3 Vande Walle, Mr. Nestor Cyriel
3 1 3 Heikkinen, Miss. Lainaboolean selection으로 row 선택하기
- numpy에서와 동일한 방식으로 해당 조건에 맞는 row만 선택
다음은 Pclass는 1 이고 30대인 승객만 모은 데이터입니다.
class_ = train_data['Pclass'] ==1
age_ = (train_data['Age']>=30)&(train_data['Age']<40)
train_data[class_&age_]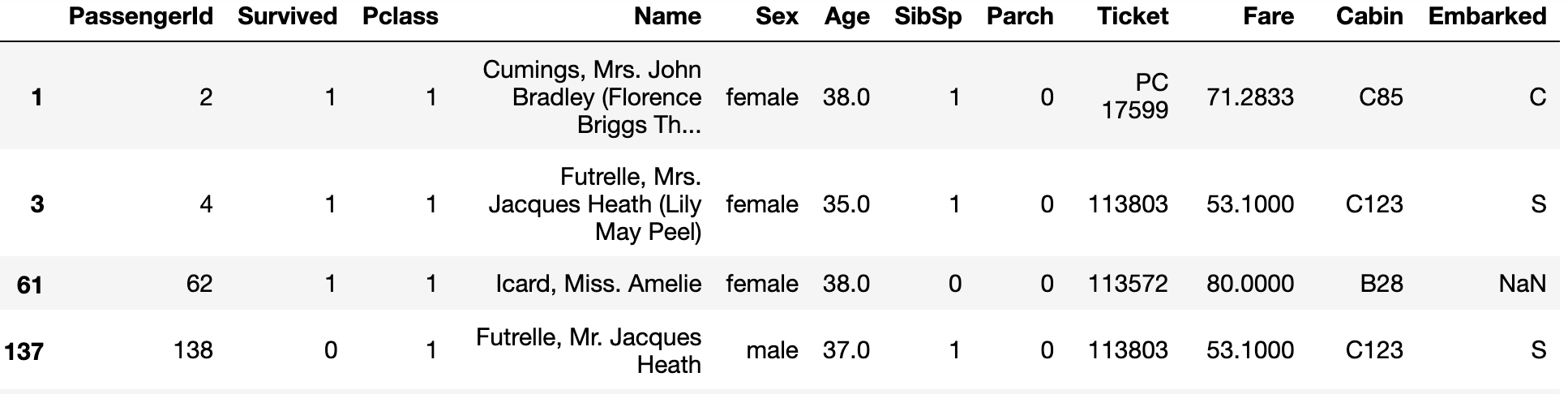
새 column 추가하기
- [] 사용하여 추가하기
- insert 함수 사용하여 원하는 위치에 추가하기
train_data['Age_double'] = train_data['Age'] * 2
train_data.head()
train_data.insert(3, 'Fare10', train_data['Fare'] / 10)
train_data.head()
column 삭제
- drop 함수를 이용한다. (axis= 1:열 , 0:행)
train_data.drop('Age_double',axis=1) # 복사본 drop
train_data.head()

NaN 값 확인 (결측지 확인)
- info함수를 통하여 개수 확인
- isna함수를 통해 boolean 타입으로 확인
train_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Fare10 891 non-null float64
4 Name 891 non-null object
5 Sex 891 non-null object
6 Age 714 non-null float64
7 SibSp 891 non-null int64
8 Parch 891 non-null int64
9 Ticket 891 non-null object
10 Fare 891 non-null float64
11 Cabin 204 non-null object
12 Embarked 889 non-null object
dtypes: float64(3), int64(5), object(5)
memory usage: 90.6+ KBinfo 메소드를 통해 확인한 결과 Age,Cabin,Embarked 피처가 결측치가 있는것을 확인된다.
이러한 결측치는 어떻게 처리 할까요?
NaN 처리 방법
- 데이터에서 삭제
- dropna 함수
- 다른 값으로 치환
- fillna 함수
dropna()메소드는 결측치가 하나라도 있는 피처가 존재하면 row자체를 삭제합니다. 이런 방법은 데이터 소실이 많이 발생하므로 많이 쓰이지는 않습니다. 그럼 fillna()메소드를 적용해 볼까요 ?
NaN 값 대체하기
- 평균으로 대체하기
- 생존자/사망자 별 평균으로 대체하기
train_data['Age'].fillna(train_data['Age'].mean()) #결측치를 평균값으로 치환.
One-hot encoding (데이터 전처리)
- 범주형 데이터는 분석단계에서 계산이 어렵기 때문에 숫자형으로 변경이 필요함
- 범주형 데이터의 각 범주(category)를 column레벨로 변경
- 해당 범주에 해당하면 1, 아니면 0으로 채우는 인코딩 기법
- pandas.get_dummies 함수 사용
- drop_first : 첫번째 카테고리 값은 사용하지 않음
pd.get_dummies(train_data,columns=['Pclass','Sex','Embarked'],drop_first=False)
group by
아래의 세 단계를 적용하여 데이터를 그룹화(groupping) (SQL의 group by 와 개념적으로는 동일, 사용법은 유사)\https://brunch.co.kr/@dan-kim/18
- 데이터 분할
- operation 적용
- 데이터 병합
다음은 Pclass,Sex 종류별로 그룹화 시킨 것입니다.
class_group = train_data.groupby('Pclass')
class_group.groups
gender_group = train_data.groupby('Sex')
gender_group.groups
groupping 함수
- 그룹 데이터에 적용 가능한 통계 함수(NaN은 제외하여 연산)
- count - 데이터 개수
- sum - 데이터의 합
- mean, std, var - 평균, 표준편차, 분산
- min, max - 최소, 최대값
class_group.count()
밑 코드는 클래스 별로 생존 확률을 나타낸 것입니다. (survived :1)
class_group.mean()['Survived']
Pclass
1 0.629630
2 0.472826
3 0.242363
Name: Survived, dtype: float64
복수 columns로 groupping 하기
- groupby에 column 리스트를 전달
- 통계함수를 적용한 결과는 multiindex를 갖는 dataframe
train_data.groupby(['Pclass','Sex']).mean()
groupby에서 loc를 활용해 특정 row를 도출하였습니다.
train_data.groupby(['Pclass', 'Sex']).mean().loc[(2, 'female')]
PassengerId 443.105263
Survived 0.921053
Age 28.722973
SibSp 0.486842
Parch 0.605263
Fare 21.970121
Age2 29.877630
Age3 28.722973
Name: (2, female), dtype: float64
transform 함수
- groupby 후 transform 함수를 사용하면 원래의 index를 유지한 상태로 통계함수를 적용
- 전체 데이터의 집계가 아닌 각 그룹에서의 집계를 계산
- 따라서 새로 생성된 데이터를 원본 dataframe과 합치기 쉬움
각각의 Pclass별로 평균값을 구해서 데이터에 다시 집어넣었습니다.
train_data.groupby('Pclass').transform(np.mean)
PassengerId Survived Age SibSp Parch Fare
0 439.154786 0.242363 25.140620 0.615071 0.393075 13.675550
1 461.597222 0.629630 38.233441 0.416667 0.356481 84.154687
2 439.154786 0.242363 25.140620 0.615071 0.393075 13.675550
3 461.597222 0.629630 38.233441 0.416667 0.356481 84.154687
4 439.154786 0.242363 25.140620 0.615071 0.393075 13.675550
... ... ... ... ... ... ...
886 445.956522 0.472826 29.877630 0.402174 0.380435 20.662183
887 461.597222 0.629630 38.233441 0.416667 0.356481 84.154687
888 439.154786 0.242363 25.140620 0.615071 0.393075 13.675550
889 461.597222 0.629630 38.233441 0.416667 0.356481 84.154687
890 439.154786 0.242363 25.140620 0.615071 0.393075 13.675550
'DNN > 머신러닝' 카테고리의 다른 글
| 성능지표 / 평가 (0) | 2021.06.25 |
|---|---|
| 사이킷런으로 타이타닉 생존자 예측 (0) | 2021.06.23 |
| 붓꽃 품종 예측 , 사이킷런 , Model Selection , 데이터 전처리 (0) | 2021.06.23 |
| Numpy(넘파이) (0) | 2021.06.22 |
| 차원 축소(Dimension Reduction) (0) | 2021.06.21 |
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!



